
index.md 8.7KB
title: More than 9 million broken links on Wikipedia are now rescued
url: https://blog.archive.org/2018/10/01/more-than-9-million-broken-links-on-wikipedia-are-now-rescued/
hash_url: adcc9f7650
As part of the Internet Archive’s aim to build a better Web, we have been working to make the Web more reliable — and are pleased to announce that 9 million formerly broken links on Wikipedia now work because they go to archived versions in the Wayback Machine.
 22 Wikipedia Language Editions with more than 9 million links now pointing to the Wayback Machine.
22 Wikipedia Language Editions with more than 9 million links now pointing to the Wayback Machine.
For more than 5 years, the Internet Archive has been archiving nearly every URL referenced in close to 300 wikipedia sites as soon as those links are added or changed at the rate of about 20 million URLs/week.
And for the past 3 years, we have been running a software robot called IABot on 22 Wikipedia language editions looking for broken links (URLs that return a ‘404’, or ‘Page Not Found’). When broken links are discovered, IABot searches for archives in the Wayback Machine and other web archives to replace them with. Restoring links ensures Wikipedia remains accurate and verifiable and thus meets one of Wikipedia’s three core content policies: ‘Verifiability’.
To date we have successfully used IABot to edit and “fix” the URLs of nearly 6 million external references that would have otherwise returned a 404. In addition, members of the Wikipedia community have fixed more than 3 million links individually. Now more than 9 million URLs, on 22 Wikipedia sites, point to archived resources from the Wayback Machine and other web archive providers.
(Broken Link) (Rescued Page)
One way to measure the real-world benefit of this work is by counting the number of click-throughs from Wikipedia to the Wayback Machine. During a recent 10-day period, the Wikimedia Foundation started measuring external link click-throughs, as part of a new research project (in collaboration with a team of researchers at Stanford and EPFL) to study how Wikipedia readers use citations and external links. Preliminary results suggest that, by far, the most popular external destination was the Wayback Machine, three times the next most popular site, books.google.com. In real numbers, on average, more than 25,000 clicks/day were made from the English Wikipedia to the Wayback Machine.
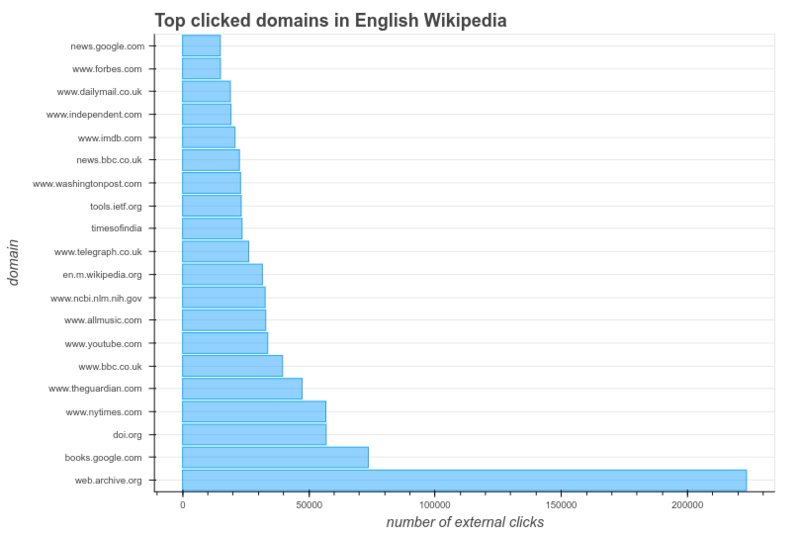
From “Research:Characterizing Wikipedia Citation Usage/First Round of Analysis”
Running IABot on a given Wikipedia site requires both technical integration and operations support as well as the approval of each related Wikipedia community. Two key people have worked on this project.
Maximilian Doerr, known in the Wikipedia world as “Cyberpower”, is a long time volunteer with the Wikipedia community and now a consultant to the Internet Archive. He is the author of the InternetArchiveBot (IABot) software.
Stephen Balbach is a long time volunteer with the Wikipedia community who collaborates with Max and the Internet Archive. He has authored programs that find and fix data errors, verifies existing archives on Wikipedia, and discovers new archives amongst Wayback’s billions of pages and across dozens of other web archive providers.
The number of rescued links, and the quality of the edits, is the result of Max and Stephen’s dedicated, creative and patient work.
What have we learned?
We learned that links to resources on the live web are fragile and not a persistently reliable way to refer to those resources. See “49% of the Links Cited in Supreme Court Decisions Are Broken”, The Atlantic, 2013.
We learned that archiving live-web linked resources, as close to the time they are linked, is required to ensure we capture those links before they go bad.
We learned that the issue of “link rot” (when once-good links return a 404, 500 or other complete failure) is only part of the problem, and that “content drift” (when the content related to a URL changes over time) is also a concern. In fact, “content drift” may be a bigger problem for reliably using external resources because there is no way for the user to know the content they are looking at is not the same as the editor had originally intended.
We learned that by working in collaboration with staff members of the Wikimedia Foundation, volunteers from the Wikipedia communities, paid contractors and the archived resources of the Wayback Machine and other web archives, we can have a material impact on the quality and reliability of Wikipedia sites and in so doing support our mission of “helping to make the web more useful and reliable”.
What is next?
We will expand our efforts to check and edit more Wikipedia sites and increase the speed which we scan those sites and fix broken links.
We will improve our processes to archive externally referenced resources by taking advantage of the Wikimedia Foundation’s new “EventStreams” web service.
We will explore how we might expand our link checking and fixing efforts to other media and formats, including more web pages, digital books and academic papers.
We will investigate and experiment with methods to support authors and editors use of archived resources (e.g. using Wayback Machine links in place of live-web links).
We will continue to work with the Wikimedia Foundation, and the Wikipedia communities world-wide, to advance tools and services to promote and support the use of persistently available and reliable links to externally referenced resources.