
index.md 32KB
title: Les technologies du Web sémantique, entre théorie et pratique
url: http://www.lespetitescases.net/les-technologies-du-web-semantique-entre-theorie-et-pratique
hash_url: 192476f231
Ce billet fait partie d'une série de quatre billets qui visent à proposer un bilan de plus de 12 ans de travail avec les technologies du Web sémantique, « Les technos du Web sémantique ont-elles tenu leurs promesses ? » :
Les technologies du Web sémantique : Pourquoi ? Comment ?
Lorsque Tim Berners-Lee crée le Web, son objectif est de proposer aux chercheurs du CERN un espace d’interopérabilité pour échanger non seulement des documents mais aussi des données structurées. Ainsi, le document qui décrit sa proposition intègre dès le départ l’idée d’aller au-delà d’un espace documentaire pour relier des entités du monde réel.
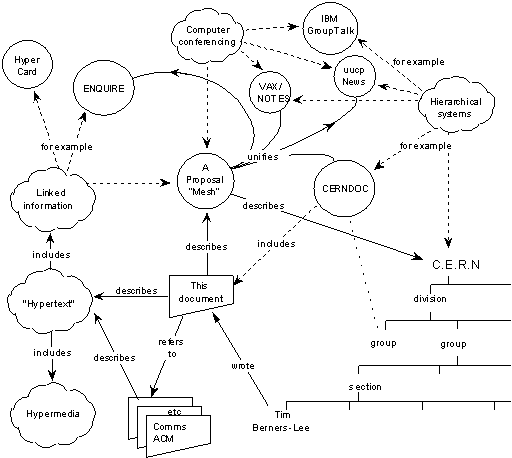
Schéma représentant la proposition de Tim Berners-Lee pour gérer l’information du CERN, Tim Berners-Lee
Tim Berners-Lee et les pionniers du Web se concentrent d’abord sur la mise au point et l’amélioration des éléments du web de documents : protocole de communication (HTTP), langage d’encodage des documents (HTML et XML) et éléments pour la mise en forme (XSLT, CSS). En 1994, année de la création du W3C, Tim Berners-Lee trace le futur du Web lors de la 1ère conférence WWW. Il revient alors sur l’idée d’intégrer dans le Web des entités du monde réel (lieu, personne, concept, oeuvre de l’esprit…) reliées entre elles par des liens typés.
Image issue de la présentation “The Need for Semantics in the Web”, Tim Berners-Lee, CC-BY
En 1998, il propose une feuille de route pour le Web sémantique. Ce document est essentiel car il contient la description des technologies nécessaires au déploiement d’un Web de données :
« The Semantic Web is a web of data, in some ways like a global database. The rationale for creating such an infrastructure is given elsewhere [Web future talks &c] here I only outline the architecture as I see it. ».
Le W3C va s’atteler dans les dix années suivantes à la mise en pratique de ces éléments.
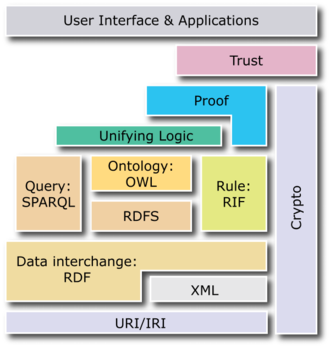
Semantic Web Stack, W3C, domaine public
{kind=link}
Ces technologies s’appuient d’abord et avant tout sur l’architecture du Web : le protocole HTTP et le système d’identifiants des URIs. Chaque entité est donc assimilée à une ressource HTTP identifiée par une URI. La description de l’entité s’appuie sur le modèle RDF : rencontre du modèle de graphe et de la logique des prédicats du 1er ordre. Ainsi, chaque élément de description forme un triplet (Sujet-Prédicat-Objet) dont le prédicat, lui-même une ressource HTTP, décrit la nature de la relation entre deux entités, sujet et objet.
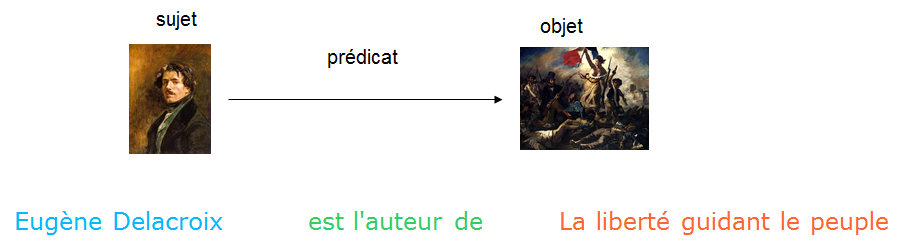
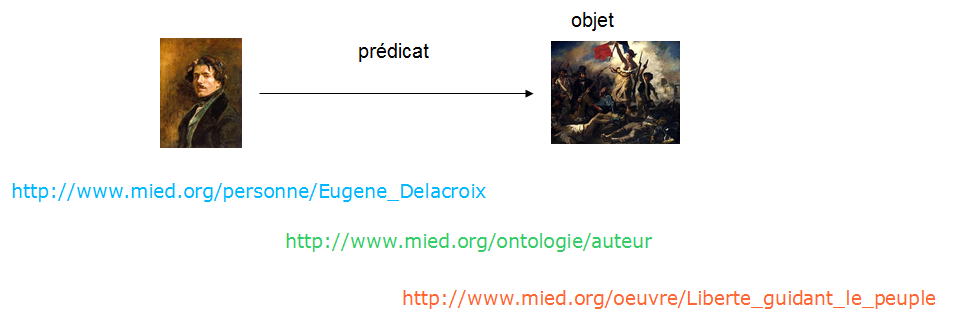
La mise en relation des différents triplets forme un graphe orienté.
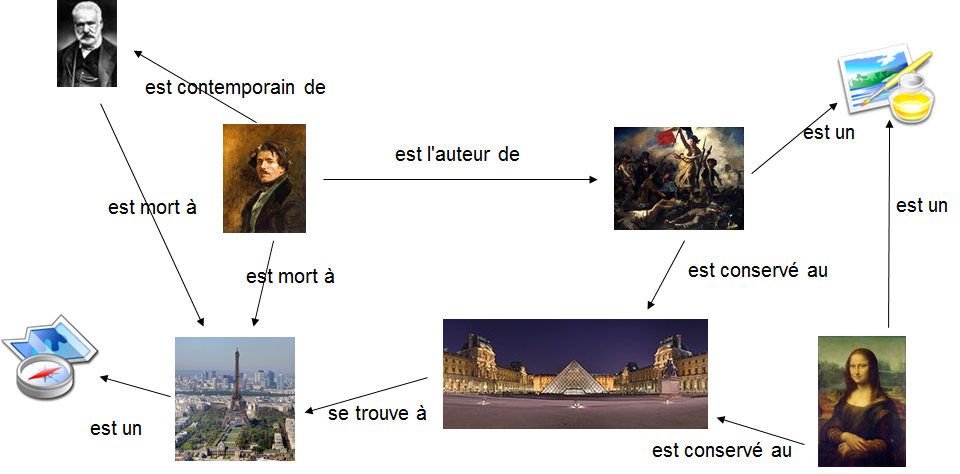
Images issues de « les technologies du Web appliquées aux données structurées »,
Emmanuelle Bermès, Gautier Poupeau, CC-BY
Au modèle RDF, s’ajoutent deux technologies principales : un ensemble de mécanismes pour décrire les modèles de données (globalement sur le principe Entités/Relations) dont les triplets sont des instanciations (RDFS/OWL) et un langage de requêtes (SPARQL).
Promesses et limites dans la pratique
Afin d’illustrer mon propos, je vous propose de revenir sur quelques expériences en insistant à chaque fois sur les raisons qui nous ont amenés à choisir les technologies du Web sémantique et les limites et/ou leçons que nous avons pu en tirer.
Le projet SPAR
Le projet Système de préservation et d’archivage réparti (SPAR) vise à donner les moyens à la Bibliothèque nationale de France d’assurer sur le très long terme la continuité de l’accès à ses collections numériques. Le système suit les principes du modèle OAIS (Open Archival Information System) qui constitue un vade mecum pour une bonne gestion et une maîtrise de l’information numérique dans le temps.
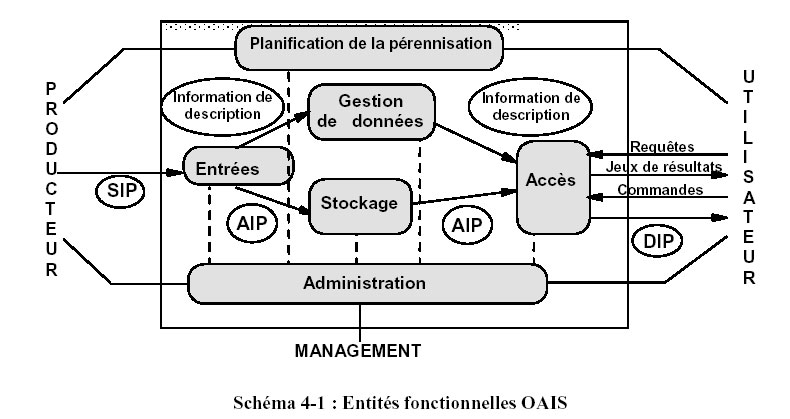
SPAR est basé sur quelques principes forts :
- séparation stricte entre les informations numériques conservées et le système qui les exploite, le système peut ainsi évoluer de manière indépendante des collections ;
- auto-documentation et auto-configuration du système, c’est-à-dire que l’ensemble des éléments du système : référentiels, code source de l’applicatif, éléments de configuration, métadonnées des informations numériques sont aussi conservés et stockés par le système sous la forme de paquets, ils sont d’ailleurs pris en compte par le système au moment de leur versement et non de manière native ;
- Tous les éléments de configuration « métiers » et les référentiels sont administrés par les experts de préservation via des paquets dit de référence nécessaires au bon fonctionnement du système, le système garantit ainsi les rôles de chacun : expert de préservation d’un côté et administrateurs du système de l’autre ;
- les interfaces, sous la forme de Web service RestFull, entre les différents éléments du système sont indépendants des technologies qui les font fonctionner ;
- les modules de l’application (dont l’architecture suit strictement le modèle OAIS) sont indépendants les uns des autres et communiquent uniquement via des Web services.
Le module “Gestion des données”, en charge du stockage et de l’interrogation des métadonnées se devait de répondre à différentes problématiques :
- toutes les métadonnées doivent être interrogeables sans idée préconçue de la manière de les interroger ;
- il faut pouvoir stocker et interroger des données hétérogènes et semi structurées ;
- il faut disposer d’un système souple et standard indépendant d’une implémentation logicielle pour simplifier l’évolution du système et la réversibilité des technologies applicatives ;
- Il faut pouvoir interroger de manière uniforme les métadonnées issues des paquets et les données de référence ;
- il faut un langage de requêtes puissant, si possible standard, accessible à des experts de préservation non informaticiens.
A l’époque (2008…), à l’issue de l’instruction, il s’est avéré que le modèle RDF et le langage de requêtes SPARQL constituaient la réponse la plus adéquate à toutes ces problématiques. Les bases de données relationnelles nous semblaient trop rigides et trop adhérentes à des logiciels particuliers. Les moteurs de recherche ne permettaient alors pas d’indexation en temps réel et posaient également problème parce qu’ils limitent l’interrogation à une entité unique. Quant aux bases de données documents, elles étaient balbutiantes ; encore aujourd’hui, elles n’offrent pas la même souplesse d’interrogation que SPARQL. Nous avons donc décidé d’implémenter l’ensemble du module “Gestion des données” avec le modèle RDF et d’exposer un sparql endpoint en guise d’API. Pour ce faire, nous avons déployé le logiciel Virtuoso qui faisait ses preuves depuis deux ans pour Dbpedia.
En premier lieu, il a fallu monter en compétence mes collègues d’Atos et les équipes de la BnF dont c’était la première expérience dans le domaine. Il a fallu ensuite créer le modèle de données, l’ontologie, puis étrenner, tester et éprouver la technologie. Et c’est là que sont apparus les premiers problèmes. Le modèle s’est bien avéré aussi souple que prévu et l’expressivité du langage de requête à la hauteur. Mais les performances et la montée en charge n’étaient pas au rendez-vous. Comme les avantages constatés étaient plus importants que les inconvénients, nous avons poursuivi dans cette voie.

Modèle de données de SPAR
Nous avons alors complexifié l’architecture avec le déploiement de plusieurs instances contenant différents ensembles de métadonnées en fonction des usages, dont une instance contenant toutes les métadonnées à indexer. Nous avons par ailleurs effectué un travail sur le volume de métadonnées indexées en les limitant à celles qui ne paraissaient pas redondantes. Last but not least, il s’avère que l’instance contenant l’ensemble des métadonnées a un nombre d’utilisateurs très limités (grosso modo on les compte sur les doigts des deux mains ;) ).
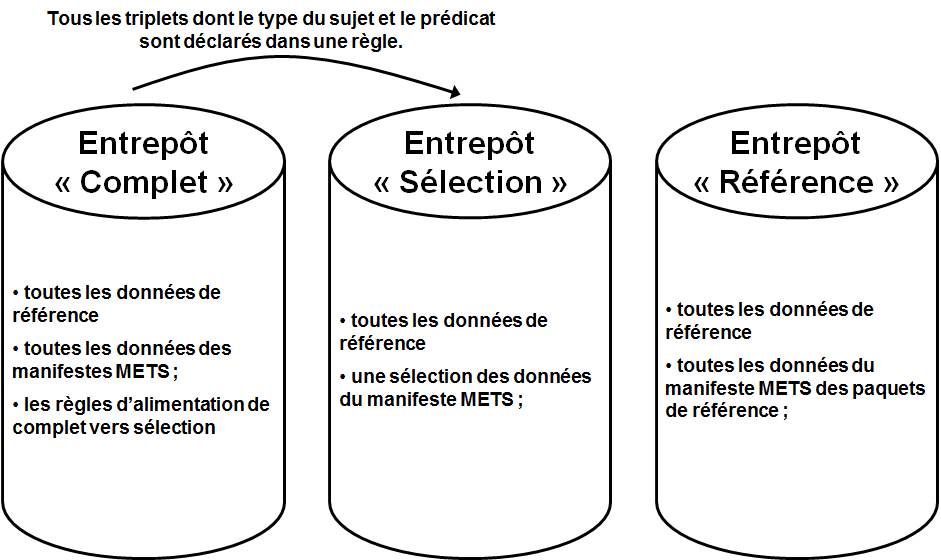
Contenu des trois entrepôts constituant le module “Gestion des données” de SPAR
Dix ans après, le système est toujours en place, la BnF est passée de la version libre (et gratuite) de Virtuoso à la version payante pour assurer la montée en charge et, d’après les échos que j’en ai, reste convaincue de ce choix. Pour ma part, j’en retiens d’abord un pari un peu fou (nous sommes quelques uns à avoir passé des nuits agitées à nous demander si c’était la bonne solution…). Si le problème de la vitesse de réponse et du nombre d’utilisateurs n’étaient pas un enjeu sur ce projet, j’en suis sorti convaincu qu’il semblait difficile d’imaginer un service en production avec un grand nombre d’utilisateurs et/ou de données, construit directement sur une base de données RDF interrogeable avec SPARQL.
Est-ce-que je préconiserais la même architecture aujourd’hui ? Je continue de penser que le graphe est le bon modèle pour répondre aux besoins de souplesse du modèle de données et d’expressivité des requêtes nécessaires à un tel système. J’aurais donc tendance à penser que le couple RDF-SPARQL reste le bon choix. Pour autant, j’étudierais les autres bases de données graphes basés sur le modèle de Property graph, en particulier celles utilisant le framework Tinkerpop et j’en limiterais l’usage à la base qui stocke l’ensemble des métadonnées. En effet, je complèterais l’architecture avec un moteur de recherche du type Solr ou ElasticSearch avec un index orienté “paquet” et un autre pour les référentiels afin d’offrir une recherche plus réactive.
Le projet Isidore
Isidore est un projet conduit par la très grande infrastructure de recherche Huma-Num (anciennement Très grand équipement Adonis) qui vise à offrir une plateforme unifiée de recherche dans les différentes ressources développées par la recherche en sciences humaines et sociales. Ce projet, démarré en 2008, a été mis en ligne en décembre 2010. Il donne accès aujourd’hui à presque 6 millions de ressources issues de plus de 6400 sources de données.
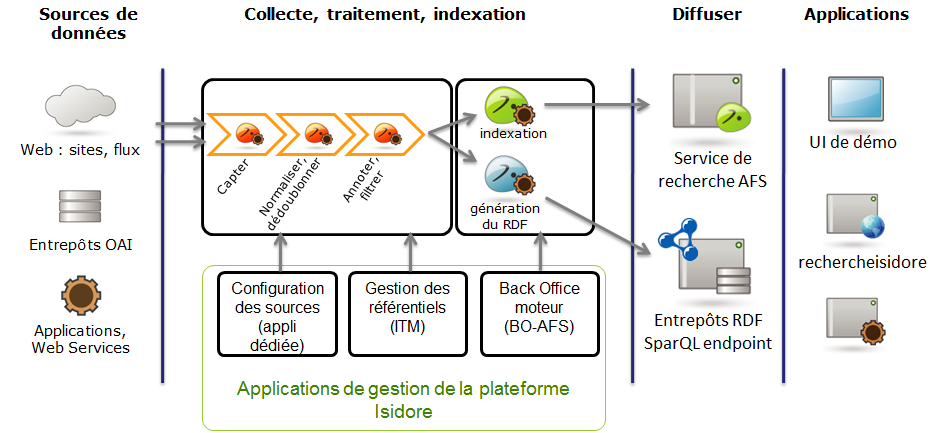
Macro-architecture d’Isidore issue de “ISIDORE, un grand projet d’ingénierie au cœur de l’avenir du web de données”, Fabrice Lacroix, Jean-Louis Villa et Bruno Perron
Les technologies du Web sémantique interviennent à différents endroits dans ce projet :
- Isidore récupère les métadonnées et le contenu selon trois méthodes différentes, l’une d’entre elles consistant à utiliser le formalisme RDFa, qui permet d’intégrer des assertions RDF dans des pages Web, pour récupérer les métadonnées de pages web dont l’URL est indiqué via le protocole Sitemap ;
- Les référentiels qui permettent d’effectuer les enrichissements sont exprimés en RDF et exploités comme tels ;
- L’ensemble des métadonnées récupérées des sources de données ou obtenues à partir des mécanismes d’enrichissement d’Isidore sont converties en RDF et stockées dans une base de données RDF à partir de laquelle elles sont exposées selon les principes du Linked Data.
En revanche, la mise en cohérence des différentes métadonnées récupérées se fait via le mapping de ces données sur un format pivot XML mis au point pour les besoins du projet.
A l’époque, le choix d’intégrer les technologies du Web sémantique constituait un pari sur l’avenir à différents niveaux. Tout d’abord, nous étions convaincus des limites du protocole OAI-PMH pour exposer les données :
- impossibilité d’exprimer différentes granularités ce qui a pour conséquence de mettre au même niveau des entités disparates ;
- limitation de base de la description au Dublin Core simple ;
- utilisation du protocole HTTP non respectueuse de sa logique (le mécanisme d’erreur n’utilise pas les codes d’erreur adéquats, mécanisme de l’hypermedia non utilisé…).
RDFa constituait à nos yeux un moyen simple pour accompagner les producteurs vers les technologies du Web sémantique et de dépasser les limites d’OAI-PMH, car cela permettait, avec un investissement qui nous paraissait limité, d’envisager une plus grande capacité de description en utilisant OAI-ORE, vocabulaire RDF apparu en 2008 et qui palliait aux limites d’OAI-PMH, et Dublin Core terms.
Par ailleurs, inspirés par les initiatives naissantes autour de l’Open Data, nous avons jugé essentiel de remettre à disposition les données. Plusieurs objectifs étaient visés :
- en tant qu’initiative publique, faire preuve de transparence quant aux données utilisées pour constituer le moteur de recherche ;
- remettre à disposition des producteurs (et, par extension, de tous) les enrichissements produits à partir de leurs données (génération d’un identifiant unique Handle, classification des ressources, annotation automatique avec des référentiels…) dans une logique de contre-don ;
- accompagner la recherche en SHS dans son appropriation des technologies du Web sémantique.
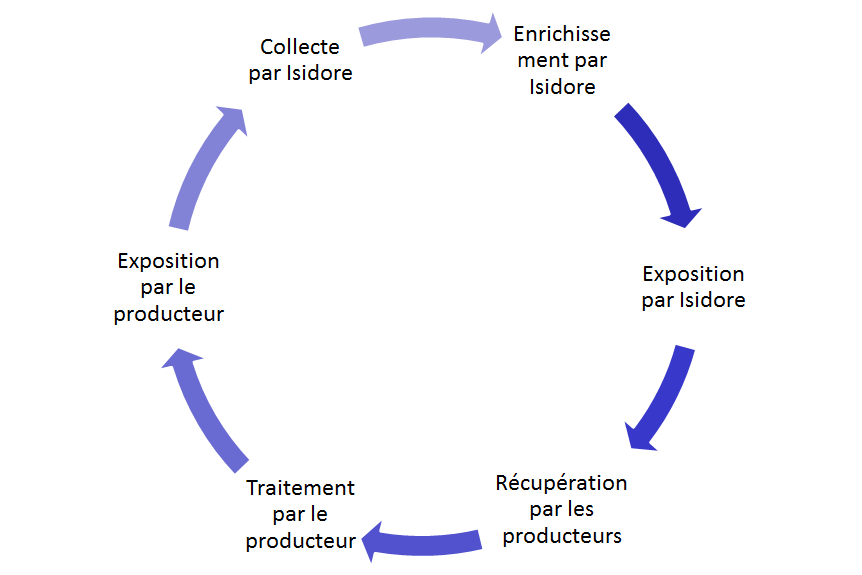
Boucle de rétroaction de la mise à disposition des données d’Isidore
Isidore à l’interface de la rencontre entre des SHS et du Web de données, Gautier Poupeau, CC-BY
Je ne suis pas le mieux placé pour tirer le bilan de ces différents paris. Avec le recul (de temps mais aussi de position), j’ai l’impression qu’ils sont à moitié tenus. Les choix étaient certainement les bons à l’époque. Ils ont eu le mérite de servir d’exemple pour faire avancer la réflexion autour de la réutilisation de données exposées, de l’usage des technologies du Web sémantique et, plus généralement, de l’interopérabilité des données de la recherche. Mais, force est de constater que les réutilisations de ces données sont assez faibles. Outre la nature des données qui ne se prête pas forcément à la réutilisation (quoique…), leur exploitation demande une courbe d’apprentissage qui n’est pas évidente. Or, les chercheurs veulent des choses simples et accessibles. Clarisse Bardiot, professeur d’histoire de l’art à l’université de Valenciennes, l’explique clairement dans ce billet. Lors de la table ronde pendant la journée d’étude organisée l’an dernier par l’ADEMEC autour des rapports entre recherche et institutions patrimoniales, Raphaëlle Lapotre, chef de produit de data.bnf.fr, ne dit pas autre chose :
« on entre surtout en contact avec les chercheurs quand ça se passe mal avec les données et ça se passe souvent mal pour plusieurs raisons. Mais, effectivement, il y a eu la question de ces fameux standards qui bouffent la vie des chercheurs [...] ils nous disent mais pourquoi vous balancez pas des csv plutôt que de vous embêter avec vos affaires de web sémantique. »
C’est un constat général dans le monde de l’Open Data, même si cela se justifie (ici l’interopérabilité) : plus les données se révèlent complexes à exploiter et moins elles font l’objet de réutilisation.
Quant à RDFa, ce formalisme s’est avéré bien plus complexe que prévu à manipuler. De plus, il n’existait à l’époque aucune initiative ou de standard de vocabulaire pour structurer ces données de manière uniforme. Nous avions préconisé le Dublin Core terms, car cela nous paraissait le plus approprié au regard du type de données. Depuis, Schema.org (sur lequel je reviendrai) est apparu et peu à peu, le formalisme RDFa a laissé la place à Json-LD. C’est bien évidemment vers ce couple que je m’orienterais aujourd’hui. Enfin, il faut constater que, malgré ses défauts, le protocole OAI-PMH reste le vecteur majoritaire par lequel Isidore récupère les données... victoire de la simplicité sur l’expressivité ? En tout cas, c’est une leçon à retenir alors qu’OAI-ORE fête ses 10 ans...
Du mashup de données….
Dans l’article fondateur sur le Web sémantique paru en 2001 dans la revue Scientifc American, les trois auteurs, Tim Berners-Lee, Ora Lassila et James Hendler, illustrent leurs propos avec un exemple dans lequel un agent logiciel parcourt différentes sources de données disponibles sur le Web et les combine en temps réel pour aboutir à une prise de rendez-vous médical. Ce cas d’usage est censé démontrer les possibilités d’exposition et d’échange des données et la capacité des technologies du Web sémantique à mettre en relation des données hétérogènes pour en déduire une information. Décentralisation, interopérabilité, inférence constituent finalement les trois objectifs principaux du Web sémantique et cet exemple en est l’illustration.
Sur le même modèle, il paraîtrait envisageable de mixer plusieurs sources de données hétérogènes exposées en RDF (ou non) pour créer des nouvelles applications dont les données seraient mises à jour en temps réel à partir des différentes sources données. C’est tout le principe des mashups de données.
Pour autant, de la théorie à la pratique, il y a un gouffre qui complexifie largement l’exercice. J’en ai fait l’expérience en réalisant plusieurs mashups seul ou à plusieurs avec les outils de l’éditeur Antidot lorsque j’en étais l’employé. Que ce soit celui sur les monuments historiques ou celui sur les musées (qui nous a valu le prix d’un concours organisé par le Ministère de la culture et l’association Wikimedia France pour la promotion de Dbpedia France), le principe général et la place des technologies du Web sémantique sont les mêmes. Nous les utilisions dans deux perspectives différentes :
- pour récupérer les sources exposées selon les principes du Linked Data ou à travers un sparql endpoint ;
- pour faire la « glue » entre les sources de données hétérogènes en construisant un graphe lui même stocké dans une base de données RDF et à partir duquel nous construisions les fichiers XML à indexer dans le moteur de recherche.
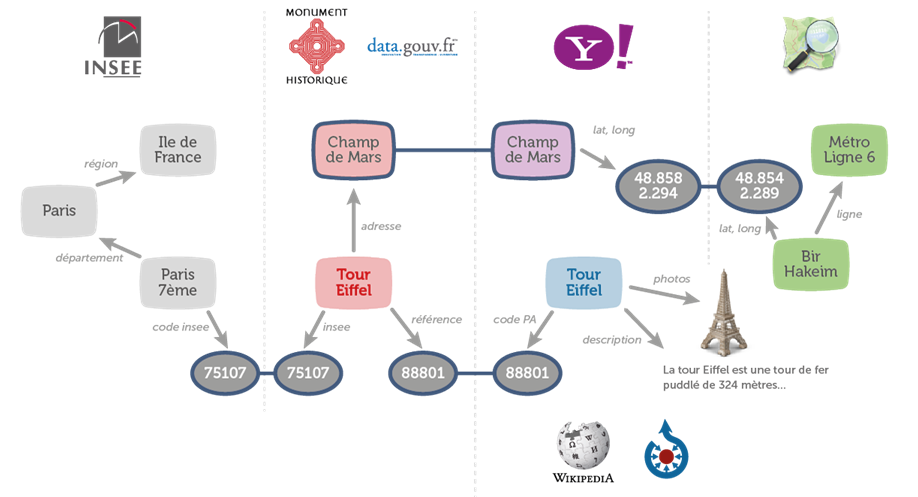
Modèle de données du projet de mashup “Monuments historiques”
La première différence qui saute aux yeux par rapport au cas d’usage exposé dans l’article de 2001 concerne la récupération des données. Dans l’état actuel des technologies et avec les problématiques de résilience du réseau, si vous souhaitez disposer d’une application disponible, rapide et scalable, vous devez récupérer les données de manière asynchrone, les traiter puis les stocker dans une base pour les exploiter localement. La promesse de décentralisation est largement écornée et cela oblige à mettre en place des mécanismes lourds pour effectuer la mise à jour des données qui ne peut se faire en temps réel.
Au delà de la complexité intrinsèque et non liée à l’utilisation des technologies du Web sémantique de ce genre d’exercice pour préparer et mettre en cohérence les données, deux autres difficultés apparaissent rapidement de par l’architecture choisie :
- convertir toutes les sources de données en RDF et mettre au point pour cela un modèle de données capable de décrire toutes les données rapatriées ;
- convertir à nouveau les données stockées dans un formalisme (Json ou XML) exploitable par un moteur de recherche, les capacités de la base de données RDF étant limitées de ce point de vue.
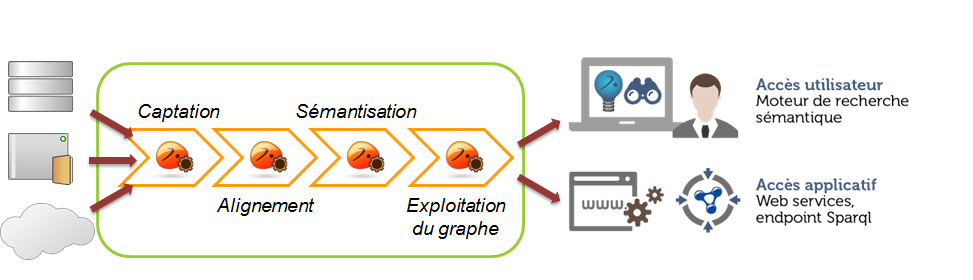
Macro-architecture de la chaîne de traitement pour le mashup “Monuments historiques”
A bien y réfléchir, on peut douter de l’utilité de l’étape de conversion et de stockage en RDF. On pourrait passer directement de la phase de récupération au stockage dans le moteur de recherche via la préparation des données. L’intérêt principal de ce choix est de séparer la donnée et sa logique de la manière de l’exploiter. De cette manière, il est possible, simple et rapide de créer différentes vues centrées autour des différentes entités du modèle ou d’inventer de nouvelles façons de naviguer dans la donnée en fonction de la manière de parcourir le graphe. évidemment, cela suppose que les réutilisateurs connaissent parfaitement la structure du graphe et maîtrisent les technologies du Web sémantique…
Cette promesse de souplesse est parfaitement tenue. Mais, à l’issue du travail, quand vous faites le rapport entre le temps passé à développer et automatiser la conversion et le stockage en RDF et le temps gagné dans l’exploitation des données, le gain immédiat est inexistant voire en défaveur de ces technologies. Il ne se justifiera (peut-être) qu’avec le temps (sans garantie…) et la création réelle de différents usages...
J’apprécie tout particulièrement cet exercice du mashup. Il est assez comparable au travail d’un cuisinier pour mettre au point un plat : il faut choisir les bons ingrédients, réfléchir à la manière de les travailler, les cuisiner et enfin effectuer le dressage. Ainsi, il fait intervenir toutes les composantes de la gestion des données : de la modélisation à la visualisation en passant par la récupération des données.
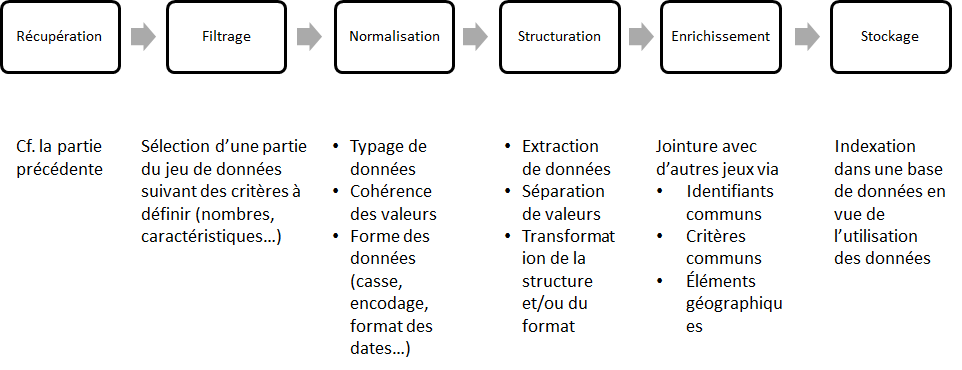
C’est la raison pour laquelle je donne depuis plusieurs années cet exercice pour évaluer les étudiants du master “Technologies numériques appliquées à l’histoire” de l’Ecole nationale des chartes. Pour autant, leur utilisation des technologies du Web sémantique se “limite” à la récupération des données via des sparql endpoint. Je ne leur demande ni de stocker les données dans une base de données RDF, ni de réexposer les données. Pourquoi le leur demanderais-je ? Dans les deux cas, c’est une perte de temps qui ne se justifie pas (plus ?)...
… au Linked enterprise Data
Libérer les données des silos existants, séparer les données des usages, lier et mettre en cohérence l’ensemble des sources de données afin de proposer de nouveaux usages et une nouvelle manière d’exploiter/explorer les données, actifs de l’organisation, le Linked Enterprise Data, concept que nous avons tenté de pousser chez Antidot, pourrait être assimilé à un mashup des données des systèmes d’informations “legacy” des organisations.
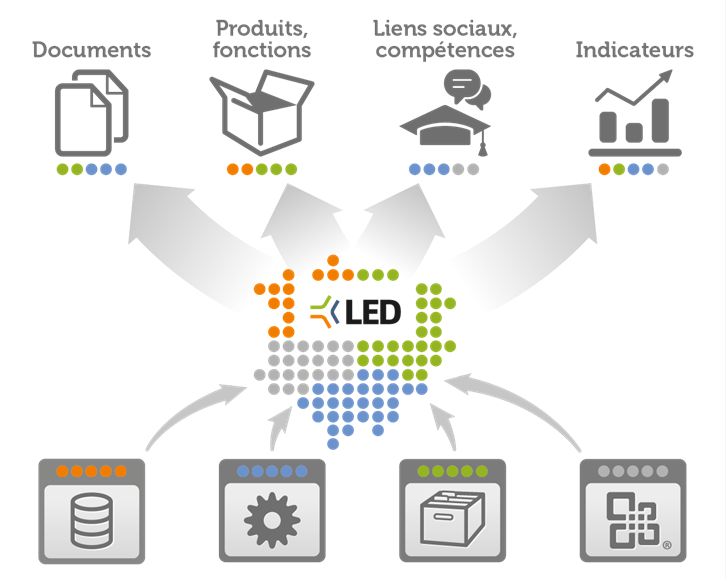
Principe général du Linked Enterprise Data issu de
“Linked Enterprise Data, les données au coeur de l’entreprise”
J’ai déjà eu l’occasion dans un précédent billet d’exposer les difficultés auxquels a été confrontée cette vision :
- problème de scalabilité et de performance ;
- complexité à sortir les données des silos et à les convertir en RDF ;
- désintérêt des organisations pour la donnée elle-même et sa logique ;
- (il)légitimité réelle ou supposée des DSI à porter une vision transverse dans l’organisation ;
- limite du modèle RDF pour exprimer la provenance des informations et, plus généralement, difficulté à contextualiser le triplet ;
- absence de compétences des développeurs dans le domaine.
Cette dernière difficulté est certainement une des plus importantes, car elle conditionne la réalisation, la supervision et la maintenabilité de tels systèmes, ces deux dernières problématiques étant souvent négligées par les spécialistes de la construction de système d’information alors qu’elles sont fondamentales. Jamais un DSI ne s’orientera vers une solution dont il n’a pas la garantie de pouvoir dans le temps assurer le maintien en condition opérationnelle.
Enfin, dans mon billet, j’ai oublié un point essentiel. Nous étions incapable de garantir un retour sur investissement (ROI). En effet, on parle de « possibilité », « capacité », « souplesse » mais, une fois l’infrastructure mise en place, il faut alors construire les usages et le DSI n’est pas certain de la volonté du métier de s’emparer d’une telle plateforme pour construire de nouveaux usages ou rationaliser son système d’information. C’est un investissement qui ne se justifie que si, au démarrage du chantier, il existe soit une volonté de refonte globale du système d’information, soit un projet clairement identifié et suffisamment stratégique pour engager un chantier aussi lourd du côté du back-office. Quand vous voyez les projets de « data lake » qui se limitent bien souvent à déverser des données tabulaires dans un système de fichiers clusterisés sans réflexion sur la cohérence des données, leur structure et leur maîtrise, on peut légitimement remettre en question la capacité des DSI à investir dans ce genre de vision...