
index.md 21KB
title: The interesting ideas in Datasette
url: https://simonwillison.net/2018/Oct/4/datasette-ideas/
hash_url: c55f3b229f
Datasette (previously) is my open source tool for exploring and publishing structured data. There are a lot of ideas embedded in Datasette. I realized that I haven’t put many of them into writing.
Publishing read-only data
Bundling the data with the code
SQLite as the underlying data engine
Far-future cache expiration
Publishing as a core feature
License and source metadata
Facet everything
Respect for CSV
SQL as an API language
Optimistic query execution with time limits
Keyset pagination
Interactive demos based on the unit tests
Documentation unit tests
Datasette provides a read-only API to your data. It makes no attempt to deal with writes. Avoiding writes entirely is fundamental to a plethora of interesting properties, many of which are expanded on further below. In brief:
- Hosting web applications with no read/write persistence requirements is incredibly cheap in 2018—often free (both ZEIT Now and a Heroku have generous free tiers). This is a big deal: even having to pay a few dollars a month is enough to dicentivise sharing data, since now you have to figure out who will pay and ensure the payments don’t expire in the future.
- Being read-only makes it trivial to scale: just add more instances, each with their own copy of the data. All of the hard problems in scaling web applications that relate to writable data stores can be skipped entirely.
- Since the database file is opened using SQLite’s immutable mode, we can accept arbitrary SQL queries with no risk of them corrupting the data.
Any time your data changes, you need to publish a brand new copy of the whole database. With the right hosting this is easy: deploy a brand new copy of your data and application in parallel to your existing live deployment, then switch over incoming HTTP traffic to your API at the load balancer level. Heroku and Zeit Now both support this strategy out of the box.
Since the data is read-only and is encapsulated in a single binary SQLite database file, we can bundle the data as part of the app. This means we can trivially create and publish Docker images that provide both the data and the API and UI for accessing it. We can also publish to any hosting provider that will allow us to run a Python application, without also needing to provision a mutable database.
The datasette package command takes one or more SQLite databases and bundles them together with the Datasette application in a single Docker image, ready to be deployed anywhere that can run Docker containers.
Datasette encourages people to use SQLite as a standard format for publishing data.
Relational database are great: once you know how to use them, you can represent any data you can imagine using a carefully designed schema.
What about data that’s too unstructured to fit a relational schema? SQLite includes excellent support for JSON data—so if you can’t shape your data to fit a table schema you can instead store it as text blobs of JSON—and use SQLite’s JSON functions to filter by or extract specific fields.
What about binary data? Even that’s covered: SQLite will happily store binary blobs. My datasette-render-images plugin (live demo here) is one example of a tool that works with binary image data stored in SQLite blobs.
What if my data is too big? Datasette is not a “big data” tool, but if your definition of big data is something that won’t fit in RAM that threshold is growing all the time (2TB of RAM on a single AWS instance now costs less than $4/hour).
I’ve personally had great results from multiple GB SQLite databases and Datasette. The theoretical maximum size of a single SQLite database is around 140TB.
SQLite also has built-in support for surprisingly good full-text search, and thanks to being extensible via modules has excellent geospatial functionality in the form of the SpatiaLite extension. Datasette benefits enormously from this wider ecosystem.
The reason most developers avoid SQLite for production web applications is that it doesn’t deal brilliantly with large volumes of concurrent writes. Since Datasette is read-only we can entirely ignore this limitation.
Since the data in a Datasette instance never changes, why not cache calls to it forever?
Datasette sends a far future HTTP cache expiry header with every API response. This means that browsers will only ever fetch data the first time a specific URL is accessed, and if you host Datasette behind a CDN such as Fastly or Cloudflare each unique API call will hit Datasette just once and then be cached essentially forever by the CDN.
This means it’s safe to deploy a JavaScript app using an inexpensively hosted Datasette-backed API to the front page of even a high traffic site—the CDN will easily take the load.
Zeit added Cloudflare to every deployment (even their free tier) back in July, so if you are hosted there you get this CDN benefit for free.
What if you re-publish an updated copy of your data? Datasette has that covered too. You may have noticed that every Datasette database gets a hashed suffix automatically when it is deployed:
https://fivethirtyeight.datasettes.com/fivethirtyeight-c9e67c4
This suffix is based on the SHA256 hash of the entire database file contents—so any change to the data will result in new URLs. If you query a previous suffix Datasette will notice and redirect you to the new one.
If you know you’ll be changing your data, you can build your application against the non-suffixed URL. This will not be cached and will always 302 redirect to the correct version (and these redirects are extremely fast).
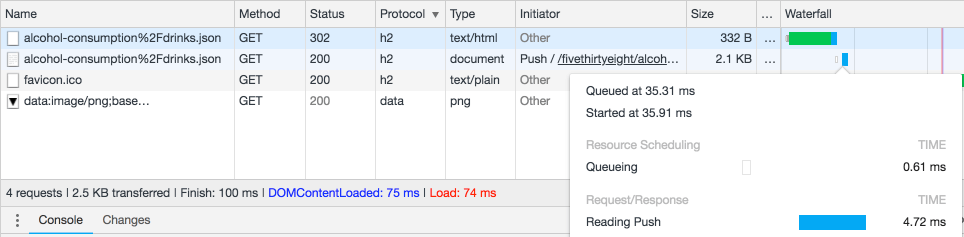
https://fivethirtyeight.datasettes.com/fivethirtyeight/alcohol-consumption%2Fdrinks.json
The redirect sends an HTTP/2 push header such that if you are running behind a CDN that understands push (such as Cloudflare) your browser won’t have to make two requests to follow the redirect. You can use the Chrome DevTools to see this in action:
And finally, if you need to opt out of HTTP caching for some reason you can disable it on a per-request basis by including ?_ttl=0 in the URL query string. —for example, if you want to return a random member of the Avengers it doesn’t make sense to cache the response:
Datasette aims to reduce the friction for publishing interesting data online as much as possible.
To this end, Datasette includes a “publish” subcommand:
# deploy to Heroku
datasette publish heroku mydatabase.db
# Or deploy to Zeit Now
datasette publish now mydatabase.db
These commands take one or more SQLite databases, upload them to a hosting provider, configure a Datasette instance to serve them and return the public URL of the newly deployed application.
Out of the box, Datasette can publish to either Heroku or to Zeit Now. The publish_subcommand plugin hook means other providers can be supported by writing plugins.
Datasette believes that data should be accompanied by source information and a license, whenever possible. The metadata.json file that can be bundled with your data supports these. You can also provide source and license information when you run datasette publish:
datasette publish fivethirtyeight.db \
--source="FiveThirtyEight" \
--source_url="https://github.com/fivethirtyeight/data" \
--license="CC BY 4.0" \
--license_url="https://creativecommons.org/licenses/by/4.0/"
When you use these options Datasette will create the corresponding metadata.json file for you as part of the deployment.
I really love faceted search: it’s the first tool I turn to whenever I want to start understanding a collection of data. I’ve built faceted search engines on top of Solr, Elasticsearch and PostgreSQL and many of my favourite tools (like Splunk and Datadog) have it as a core feature.
Datasette automatically attempts to calculate facets against every table. You can read more about the Datasette Facets feature here—as a huge faceted search fan it’s one of my all-time favourite features of the project. Now I can add SQLite to the list of technologies I’ve used to build faceted search!
CSV is by far the most common format for sharing and publishing data online. Almost every useful data tool has the ability to export to it, and it remains the lingua franca of spreadsheet import and export.
It has many flaws: it can’t easily represent nested data structures, escaping rules for values containing commas are inconsistently implemented and it doesn’t have a standard way of representing character encoding.
Datasette aims to promote SQLite as a much better default format for publishing data. I would much rather download a .db file full of pre-structured data than download a .csv and then have to re-structure it as a separate piece of work.
But interacting well with the enormous CSV ecosystem is essential. Datasette has deep CSV export functionality: any data you can see, you can export—including the results of arbitrary SQL queries. If your query can be paginated Datasette can stream down every page in a single CSV file for you.
Datasette’s sister-tool csvs-to-sqlite handles the other side of the equation: importing data from CSV into SQLite tables. And the Datasette Publish web application allows users to upload their CSVs and have them deployed directly to their own fresh Datasette instance—no command line required.
A lot of people these days are excited about GraphQL, because it allows API clients to request exactly the data they need, including traversing into related objects in a single query.
Guess what? SQL has been able to do that since the 1970s!
There are a number of reasons most APIs don’t allow people to pass them arbitrary SQL queries:
- Security: we don’t want people messing up our data
- Performance: what if someone sends an accidental (or deliberate) expensive query that exhausts our resources?
- Hiding implementation details: if people write SQL against our API we can never change the structure of our database tables
Datasette has answers to all three.
On security: the data is read-only, using SQLite’s immutable mode. You can’t damage it with a query—INSERT and UPDATEs will simply throw harmless errors.
On performance: SQLite has a mechanism for canceling queries that take longer than a certain threshold. Datasette sets this to one second by default, though you can alter that configuration if you need to (I often bump it up to ten seconds when exploring multi-GB data on my laptop).
On hidden implementation details: since we are publishing static data rather than maintaining an evolving API, we can mostly ignore this issue. If you are really worried about it you can take advantage of canned queries and SQL view definitions to expose a carefully selected forward-compatible view into your data.
I mentioned Datasette’s SQL time limits above. These aren’t just there to avoid malicious queries: the idea of “optimistic SQL evaluation” is baked into some of Datasette’s core features.
Consider suggested facets—where Datasette inspects any table you view and tries to suggest columns that are worth faceting against.
The way this works is Datasette loops over every column in the table and runs a query to see if there are less than 20 unique values for that column. On a large table this could take a prohibitive amount of time, so Datasette sets an aggressive timeout on those queries: just 50ms. If the query fails to run in that time it is silently dropped and the column is not listed as a suggested facet.
Datasette’s JSON API provides a mechanism for JavaScript applications to use that same pattern. If you add ?_timelimit=20 to any Datasette API call, the underlying query will only get 20ms to run. If it goes over you’ll get a very fast error response from the API. This means you can design your own features that attempt to optimistically run expensive queries without damaging the performance of your app.
SQL pagination using OFFSET/LIMIT has a fatal flaw: if you request page number 300 at 20 per page the underlying SQL engine needs to calculate and sort all 6,000 preceding rows before it can return the 20 you have requested.
This does not scale at all well.
Keyset pagination (often known by other names, including cursor-based pagination) is a far more efficient way to paginate through data. It works against ordered data. Each page is returned with a token representing the last record you saw, then when you request the next page the engine merely has to filter for records that are greater than that tokenized value and scan through the next 20 of them.
(Actually, it scans through 21. By requesting one more record than you intend to display you can detect if another page of results exists—if you ask for 21 but get back 20 or less you know you are on the last page.)
Datasette’s table view includes a sophisticated implementation of keyset pagination.
Datasette defaults to sorting by primary key (or SQLite rowid). This is perfect for efficient pagination: running a select against the primary key column for values greater than X is one of the fastest range scan queries any database can support. This allows users to paginate as deep as they like without paying the offset/limit performance penalty.
This is also how the “export all rows as CSV” option works: when you select that option, Datasette opens a stream to your browser and internally starts keyset-pagination over the entire table. This keeps resource usage in check even while streaming back millions of rows.
Here’s where Datasette gets fancy: it handles keyset pagination for any other sort order as well. If you sort by any column and click “next” you’ll be requesting the next set of rows after the last value you saw. And this even works for columns containing duplicate values: If you sort by such a column, Datasette actually sorts by that column combined with the primary key. The “next” pagination token it generates encodes both the sorted value and the primary key, allowing it to correctly serve you the next page when you click the link.
Try clicking “next” on this page to see keyset pagination against a sorted column in action.
I love interactive demos. I decided it would be useful if every single release of Datasette had a permanent interactive demo illustrating its features.
Thanks to Zeit Now, this was pretty easy to set up. I’ve actually taken it a step further: every successful push to master on GitHub is also deployed to a permanent URL.
Some examples:
The database that is used for this demo is the exact same database that is created by Datasette’s unit test fixtures. The unit tests are already designed to exercise every feature, so reusing them for a live demo makes a lot of sense.
You can view this test database on your own machine by checking out the full Datasette repository from GitHub and running the following:
python tests/fixtures.py fixtures.db metadata.json
datasette fixtures.db -m metadata.json
Here’s the code in the Datasette Travis CI configuration that deploys a live demo for every commit and every released tag.
I wrote about the Documentation unit tests pattern back in July.
Datasette’s unit tests include some assertions that ensure that every plugin hook, configuration setting and underlying view class is mentioned in the documentation. A commit or pull request that adds or modifies these without also updating the documentation (or at least ensuring there is a corresponding heading in the docs) will fail its tests.
Datasette’s documentation is in pretty good shape now, and the changelog provides a detailed overview of new features that I’ve added to the project. I presented Datasette at the PyBay conference in August and I’ve published my annotated slides from that talk. I was interviewed about Datasette for the Changelog podcast in May and my notes from that conversation include some of my favourite demos.
Datasette now has an official Twitter account—you can follow @datasetteproj there for updates about the project.