
index.md 67KB
title: What Makes Software Good?
url: https://medium.com/@mbostock/what-makes-software-good-943557f8a488
hash_url: b0e68315fb
As someone who creates open-source software, I spend a lot of time thinking about how to make software better.
This is unavoidable: there’s an unending stream of pleas for help on Stack Overflow, in GitHub issues and Slack mentions, in emails and direct messages. Fortunately, you also see people succeed and make fantastic things beyond your imagination, and knowing you helped is a powerful motivation to keep at it.
So you wonder: what qualities of software lead people to succeed or fail? How can I improve my software and empower more people to be successful? Can I articulate any guiding principles, or do I just have intuition that I apply on a case-by-case basis? (Thinking about something and externalizing — articulating — that thought are two very different activities.) Perhaps something like Dieter Ram’s principles for good design, tailored for software?
Good design is innovative.
Good design makes a product useful.
Good design is aesthetic.
Good design makes a product understandable.
Good design is unobtrusive.
Good design is honest.
Good design is long-lasting.
Good design is thorough down to the last detail.
Good design is environmentally-friendly.
Good design is as little design as possible.
I’ve tried in the past to talk about big picture stuff. Things like finding the smallest interesting problem, identifying and minimizing harmful biases in tools, or leveraging related technologies and standards.
The big picture is important — probably more important than what I’m writing about today — but I can’t help but feel that big picture advice is sometimes impractical or impossible to apply. Or worse, truisms. Like saying, “Make it as simple as possible, but no simpler.” Well, duh. We all want things to be simpler. But we may not know what to sacrifice in order to achieve that goal.
And even if you get the big picture right, there’s no guarantee your design will be successful. The execution of an idea matters as much as the idea itself. The devil is in the details.
If I can’t offer actionable big picture advice, perhaps there’s lesser advice that would be useful. A practical inspiration is Green & Petre, whose “cognitive dimensions” framework defines a set of “discussion tools” to “raise the level of discourse” about the usability of “information artifacts” such as code.
Abstraction gradient
Closeness of mapping
Consistency
Diffuseness
Error-proneness
Hard mental operations
Hidden dependencies
Premature commitment
Progressive evaluation
Role-expressiveness
Secondary notation
Viscosity
Visibility
It’s not perfect; no framework is. It was conceived to study visual programming environments, and sometimes feels specific to that application. (Consider visibility, which refers to seeing all the code simultaneously. Is any software today small enough to be visible in its entirety on a single screen? Perhaps modularity would be better?) I find it difficult to assign some usability problems to one dimension or another. (Both hidden dependencies and role-expressiveness suggest I thought the code would do something other than what it did.) Still, it’s a good starting point for thinking about the “cognitive consequences” of software design.
I won’t be defining a general framework. But I do have some observations I’d like to share, and this is as good a time as any to perform a post hoc rationalization of the last year or so I’ve spent on D3 4.0.
I’m not revisiting the “big picture” design of D3. I’m quite happy with concepts like the data join, scales, and layouts decoupled from visual representation. There’s interesting research here, of course, but it hasn’t been my recent focus.
I’m breaking D3 into modules — to make it usable in more applications, easier for others to extend, and more fun to develop — but I’m also identifying and fixing a surprising number of quirks and flaws in the API. Stuff that’s easily overlooked, but that I believe causes real pain and limits what people can do.
I worry sometimes that the changes are trivial, especially when taken individually. I hope to convince you that they are not. I worry because I think we (that is, people who write software) tend to undervalue the usability of programming interfaces, instead considering more objective qualities that are easier to measure: functionality, performance, correctness.
Those qualities matter, but poor usability has a real cost. Just ask anyone who has struggled to decipher a confusing block of code, or pulled their hair out fighting the debugger. We need to get better at evaluating usability sooner, and better at making software usable in the first place.


You can’t pick up a piece of code and feel its weight or texture in your hands. Code is an “information artifact” rather than a physical or graphical one. You interact with APIs through the manipulation of text in an editor or on the command line.
Yet this is interaction by the standard definition, subject to the complexities of human factors. So we should evaluate code, like any tool, not merely on whether it performs its intended task, but whether it is easy to become proficient, and whether using it is efficient and enjoyable. We should consider the affordances and even the aesthetics of code. Is it understandable? Is it frustrating? Is it beautiful?
Programming interfaces are user interfaces. Or, to put it another way: Programmers are people, too. On the subject of undervaluing the human aspect of design, again hear Rams:
“Indifference towards people and the reality in which they live is actually the one and only cardinal sin in design.”
This implies, for one, that good documentation does not excuse bad design. You can ask people to RTFM, but it is folly to assume they have read everything and memorized every detail. The clarity of examples, and the software’s decipherability and debuggability in the real world, are likely far more important. Form must communicate function.
With that preamble, here are some of the changes I’m making to D3 with an eye towards usability. But first a crash course on D3’s data-join.
Case 1. Removing the magic of enter.append.
“D3” stands for Data-Driven Documents. The data refers to the thing you want to visualize, and the document refers to its visual representation. It’s called a “document” because D3 is based on the standard model for web pages: the Document Object Model.
A simple page might look like this:
<!DOCTYPE html>
<svg width="960" height="540">
<g transform="translate(32,270)">
<text x="0">b</text>
<text x="32">c</text>
<text x="64">d</text>
<text x="96">k</text>
<text x="128">n</text>
<text x="160">r</text>
<text x="192">t</text>
</g>
</svg>
This happens to be an HTML document containing an SVG element, but you don’t need to know the semantics of every element and attribute to grasp the concept. Just know that each element, such as <text>…</text> for a piece of text, is a discrete graphical mark. Elements are grouped hierarchically (the <svg> contains the <g>, which contains the <text>, and so on) so that you can position and style groups of elements.
A corresponding simple dataset might look like this:
var data = [
"b",
"c",
"d",
"k",
"n",
"r",
"t"
];
This dataset is an array of strings. (A string is a character sequence, though the strings here are individual letters.) But data can have any structure you want, if you can represent it in JavaScript.
For each entry (each string) in the data array, we need a corresponding <text> element in the document. This is the purpose of the data-join: a concise method for transforming a document — adding, removing, or modifying elements — so that it corresponds to data.
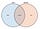
The data-join takes as input an array of data and an array of document elements, and returns three selections:
- The enter selection represents “missing” elements (incoming data) that you may need to create and add to the document.
- The update selection represents existing elements (persisting data) that you may need to modify (for example, repositioning).
- The exit selection represents “leftover” elements (outgoing data) that you may need to remove from the document.
The data-join doesn’t modify the document itself. It computes enter, update and exit, and then you apply the desired operations to each. That affords expressiveness: for example, to animate elements as they enter and exit.

As you can imagine, the data-join is something you use often — when first creating a visualization, and again whenever the data changes. The usability of this feature is hugely important to D3’s overall usefulness. It looks like this:
var text = g
.selectAll("text")
.data(data, key); // JOIN
text.exit() // EXIT
.remove();
text // UPDATE
.attr("x", function(d, i) { return i * 32; });
text.enter() // ENTER
.append("text")
.attr("x", function(d, i) { return i * 32; }) // 🌶
.text(function(d) { return d; });
I’m glossing over a few details (like the key function that assigns data to elements), but I hope the gist is conveyed. After joining to data, the code above removes exiting elements, repositions updating elements, and appends entering elements.
There’s an irksome usability problem in the above code, which I’ve marked with a hot pepper 🌶. It is duplicate code: setting the x attribute on enter and update.
It’s common to apply operations to both entering and updating elements. If an element is updating (i.e., you’re not creating it from scratch), you may need to modify it to reflect the new data. Those modifications often also apply to entering elements, since they must reflect the new data, too.
D3 2.0 introduced a change to address this duplication: appending to the enter selection would now copy entering elements into the update selection. Thus, any operations applied to the update selection after appending to the enter selection would apply to both entering and updating elements, and duplicate code could be eliminated:
var text = g
.selectAll("text")
.data(data, key); // JOIN
text.exit() // EXIT
.remove();
text.enter() // ENTER
.append("text") // 🌶
.text(function(d) { return d; });
text // ENTER + UPDATE
.attr("x", function(d, i) { return i * 32; });
Alas, this made usability worse.
First, there’s no indication of what’s happening under the hood (poor role-expressiveness, or perhaps a hidden dependency). Most of the time, selection.append creates, appends and selects new elements; it does that here, but it also silently modifies the update selection. Surprise!
Second, the code is now dependent on the order of operations: if the operations to the update selection are applied before enter.append, they only affect updating nodes; if they occur after, they affect both entering and updating. The goal of the data-join is to eliminate such intricate logic, and to enable a more declarative specification of document transformations without complicated branching and iteration. The code might look simple, but it’s brushed the complexity under the rug.
D3 4.0 removes the magic of enter.append. (In fact, D3 4.0 removes the distinction between enter and normal selections entirely: there is now only one class of selection.) In its place, a new selection.merge method can unify the enter and update selections:
var text = g
.selectAll("text")
.data(data, key); // JOIN
text.exit() // EXIT
.remove();
text.enter() // ENTER
.append("text")
.text(function(d) { return d; })
.merge(text) // ENTER + UPDATE
.attr("x", function(d, i) { return i * 32; });
This eliminates the duplicate code without corrupting the behavior of a common method (selection.append) and without introducing a subtle dependency on ordering. Furthermore, the selection.merge method serves as a signpost to unfamiliar readers, which they can look up in the documentation.
Maxim 1. Avoid overloading meaning.
What can we learn from this failure? D3 3.x violated a Rams principle: good design makes a product understandable. In cognitive dimension terms, it had poor consistency because selection.append behaved differently on enter selections, and thus the user can’t extend understanding of normal selections to enter. It had poor role-expressiveness because the latter behavior wasn’t obvious. And there’s a hidden dependency: operations on the text selection must be run after appending to enter, though nothing in the code makes this requirement apparent.
D3 4.0 avoids overloading meaning. Rather than silently adding functionality to enter.append — even if it is useful in a common case — selection.append always only appends elements. If you want to merge selections, you need a new method! Hence, selection.merge.
Case 2. Removing the magic of transition.each.
A transition is a selection-like interface for animating changes to the document. Instead of changing the document instantaneously, transitions smoothly interpolate the document from its current state to the desired target state over a given duration.
Transitions can be heterogeneous: sometimes you want to synchronize a transition across multiple selections. For example, to transition an axis, you must reposition tick lines and labels simultaneously:

One way of specifying such a transition:
d3.selectAll("line").transition()
.duration(750)
.attr("x1", x)
.attr("x2", x);d3.selectAll("text").transition() // 🌶
.duration(750) // 🌶
.attr("x", x);(Here x is a function, such as a linear scale, to compute the horizontal position of each tick from its corresponding data value.)
The two peppers suggest caution. Again there’s duplicate code: the transitions for the line and text elements are created independently, so we must repeat the timing parameters such as delay and duration.
A more subtle problem is that there’s no guarantee the two transitions are synchronized! The second transition is created after the first, so its start time is slightly later. A difference of a millisecond or two may not be visible here, but it might in other applications.
D3 2.8 introduced a new feature to synchronize heterogenous transitions such as these: it added magic to transition.each — a method for iterating over each selected element — such that any new transition created within the callback would inherit timing from the surrounding transition. So now you could say:
var t = d3.transition()
.duration(750);
t.each(function() {
d3.selectAll("line").transition() // 🌶
.attr("x1", x)
.attr("x2", x); d3.selectAll("text").transition() // 🌶
.attr("x", x);
});Like enter.append, this has poor usability: it changes the behavior of existing methods (selection.each and selection.transition) with no indication that the behavior has changed. If you create a second transition on a given selection, that new transition doesn’t pre-empt the old one; you’re just reselecting the old transition. Oops!
This example is regrettably contrived for the sake of pedagogy. There’s another, cleaner way (even in D3 3.x) to synchronize transitions across selections using transition.select and transition.selectAll:
var t = d3.transition()
.duration(750);
t.selectAll("line")
.attr("x1", x)
.attr("x2", x);t.selectAll("text")
.attr("x", x);Here, the transition t on the document root is applied to the line and text elements by selecting them. This is an elegant, but limited, solution: the transition can only be applied to a new selection, and not to an existing selection. Reselecting is always possible, but this is unnecessary work and unnecessary code (particularly for the transient enter, update, and exit selections returned by the data-join).
D3 4.0 removes the magic of transition.each; it now shares the implementation of selection.each. Instead, selection.transition can be passed a transition, causing the new transition to inherit timing from the specified transition. Now we can achieve the desired synchronization when creating new selections:
var t = d3.transition()
.duration(750);
d3.selectAll("line").transition(t)
.attr("x1", x)
.attr("x2", x);d3.selectAll("text").transition(t)
.attr("x", x);Or when using existing selections:
var t = d3.transition()
.duration(750);
line.transition(t)
.attr("x1", x)
.attr("x2", x);
text.transition(t)
.attr("x", x);
This new design arguably corrupts the behavior of selection.transition. But a new method signature (a method with the same name, but different arguments) is a fairly common design pattern, and at least the difference in behavior is localized to a single call and explicitly enabled at the call site.
Maxim 2. Avoid modal behavior.
This is an extension of the previous maxim, avoid overloading meaning, for a more egregious violation. Here, D3 2.8 introduced inconsistency with selection.transition, but the behavioral trigger was not a different class; it was simply being inside a call to transition.each. A remarkable consequence of this design is that you can change the behavior of code you didn’t write by wrapping it with transition.each!
If you see code that’s setting a global variable to trigger a global change in behavior, chances are it’s a bad idea.
In hindsight, this one is particularly glaring. What was I thinking? Am I a failed designer? There is consolation in understanding why bad ideas are attractive: it is easier to recognize and reject them in the future. Here, I recall trying to minimize perceived complexity by avoiding new methods. However, this is a clear example where introducing new methods (or signatures) is simpler than overloading existing ones.
Case 3. Removing the magic of d3.transition(selection).
A powerful concept in most modern programming languages is the ability to define reusable units of code as functions. By wrapping code in a function, you can call it wherever you want, without resorting to copy-and-paste. While some software libraries define their own abstractions for reusing code (say, extending a chart type), D3 is agnostic about how you encapsulate code, and I recommend just using a function.
Since selections and transitions share many methods, such as selection.style and transition.style for setting style properties, you can write a function that operates on either selections or transitions. For example:
function makeitred(context) {
context.style("color", "red");
}You can pass makeitred a selection to instantaneously set the body’s text color to red:
d3.select("body").call(makeitred);But you can also pass makeitred a transition, in which case the text color will fade to red over a short duration:
d3.select("body").transition().call(makeitred);This approach is taken by D3’s built-in components such as axes and brushes, and also by behaviors such as zoom.
A gotcha of this approach, however, is that transitions and selections do not have identical APIs, so not all code can be agnostic. Some operations, such as computing a data-join to update axis ticks, requires selections.
D3 2.8 introduced another misguided feature for this use case: it overloaded d3.transition, which normally returns a new transition on the document root. If you passed a selection to d3.transition, and you were inside a transition.each callback, then d3.transition would return a new transition on the specified selection; otherwise it would just return the specified selection. (This feature was added in the same commit as the transition.each flaw discussed above. When it rains, it pours!)
You should infer from my cumbersome description that this feature was a bad idea. But let’s take a closer look, for science. Here’s an equivalent way of writing the above makeitred function that allows some code (using s) to be restricted to the selection API with other code (using t) instead applied to the transition API if context is a transition:
function makeitred(context) {
context.each(function() { // 🌶
var s = d3.select(this),
t = d3.transition(s); // 🌶
t.style("color", "red");
});
}The transition.each magic is here, too: d3.transition calls selection.transition and is inside a transition.each callback, so the new transition inherits timing from the surrounding transition. There’s new confusion in that d3.transition doesn’t do what it normally does. And there’s confusion in that context and t are unknown types — either a selection or a transition — though perhaps that’s justified by the convenience of calling makeitred on either selections or transitions.
D3 4.0 removes d3.transition(selection); d3.transition can now only be used to create a transition on the document root, as with d3.selection. To disambiguate a selection from a transition, do what you normally do in JavaScript to check types: instanceof, or if you prefer, duck typing.
function makeitred(context) {
var s = context.selection ? context.selection() : context,
t = context;
t.style("color", "red");
}Notice that in addition to removing the magic of transition.each and d3.transition, the new makeitred function avoids transition.each entirely, while still allowing you to write code that is selection-specific using D3 4.0’s new transition.selection method. This is a contrived example in that the selection s isn’t used, and t has the same value as context, and thus it can be trivially reduced back to the original definition:
function makeitred(context) {
context.style("color", "red");
}But that’s my point. The need for some selection-specific code should not require a complete rewrite to use transition.each! Green & Petre call that premature commitment.
Maxim 3. Favor parsimony.
The d3.transition method was trying to be clever and combine two operations. The first is checking whether you’re inside the magic transition.each callback. If you are, the second is deriving a new transition from a selection. Yet the latter is already possible using selection.transition, so d3.transition was trying to do too much and hiding too much as a result.
Case 4. Repeating transitions with d3.active.
D3 transitions are finite sequences. Most often, a transition is just a single stage, transitioning from the current state of the document to the desired target state. However, sometimes you want more elaborate sequences that go through several stages:

(Use caution when staging animations! Read Animated Transitions in Statistical Data Graphics by Heer & Robertson.)
Sometimes, you might even want to repeat a sequence indefinitely, as in this toy example of circles undulating back and forth:

D3 has no dedicated method for infinite transition sequences, but you can create a new transition when an old one ends by listening to transition start or end events. This led to the most confusing example code I’ve ever written:
svg.selectAll("circle")
.transition()
.duration(2500)
.delay(function(d) { return d * 40; })
.each(slide); // 🌶function slide() {
var circle = d3.select(this);
(function repeat() {
circle = circle.transition() // 🌶
.attr("cx", width)
.transition()
.attr("cx", 0)
.each("end", repeat);
})(); // 🌶
}Three peppers! I’m hesitant to even attempt an explanation after the “cognitive consequences” we’ve sustained from the earlier ones. But you’ve made it this far, so I’ll do my best.
First, transition.each invokes the slide callback, iterating over each circle. The slide callback defines a self-invoking repeat closure which captures the circle variable. Initially circle represents a selection of one circle element; the first stage of the transition is thus created using selection.transition, inheriting timing from the surrounding transition! The second stage is created using transition.transition so that it begins when the first stage ends. This second stage is then assigned to circle. Lastly, each time the two-stage transition sequence ends, repeat is called, repeating and redefining the circle transition.
Also, did you notice that transition.each with one argument does something completely different than transition.each with two arguments? I probably need a fourth pepper.
Phew!
Now let’s compare to D3 4.0:
svg.selectAll("circle")
.transition()
.duration(2500)
.delay(function(d) { return d * 40; })
.on("start", slide);function slide() {
d3.active(this)
.attr("cx", width)
.transition()
.attr("cx", 0)
.transition()
.on("start", slide);
}D3 4.0 introduces d3.active, which returns the active transition on the specified element. This eliminates the need to capture a local variable for each circle (the circle variable), and by extension the need for a self-invoking closure (the repeat function), and the need for transition.each magic!
Maxim 4. Obscure solutions are not solutions.
This is a case where there’s a valid way to solve a problem, but it’s so intricate and brittle that you’re unlikely to discover it and you’re never going to remember it. I wrote the library and I still had to Google it.
Also, it was ugly.
Case 5. Freezing time in the background.
An infinitely-repeating transition in D3 3.x exhibits interesting behavior if you leave it open in a background tab for a long time. Well, by “interesting” I mean it looks like this:

This happens because when the tab is returned to the foreground, it diligently attempts to show all the transitions you missed. If a tab defines transitions on hundreds of elements per second when in the foreground, and is backgrounded for several hours, that could be millions of transitions!
Of course there’s no point in running these transitions: they are scheduled in the past and will end as soon as they start. But since an infinite chain of transitions never interrupts itself, the transitions must proceed.
D3 4.0 fixes this problem by changing the definition of time. Transitions don’t typically need to be synchronized with absolute time; transitions are primarily perceptual aids for tracking objects across views. D3 4.0 therefore runs on perceived time, which only advances when the page is in the foreground. When a tab is backgrounded and returned to the foreground, it simply picks up as if nothing had happened.
Maxim 5. Question your assumptions.
Sometimes a design flaw may not be fixable by adding or changing a single method. Instead, there may be an underlying assumption that needs reexamination — like that time is absolute.
Case 6. Cancelling transitions with selection.interrupt.
Transitions are often initiated by events, such as the arrival of new data over the wire or user interaction. Since transitions are not instantaneous — they have a duration — that could mean multiple transitions competing to control the fate of elements. To avoid this, transitions should be exclusive, allowing a newer transition to pre-empt (to interrupt) an older one.
However, such exclusivity should not be global. Multiple concurrent transitions should be allowed, as long as they operate on different elements. If you quickly toggle between stacked and grouped bars below, you can send waves rippling across the chart:
D3’s transitions are exclusive per element by default. If you need greater exclusivity, there’s selection.interrupt, which interrupts the active transition on the selected elements.
The problem with selection.interrupt in D3 3.x is that it does not also cancel pending transitions that are scheduled on selected elements. There’s not a good justification for this oversight — blame can likely be placed on a different design flaw in D3 3.x’s timers, which can’t be stopped externally, therefore making it somewhat awkward to cancel transitions. (Instead, pre-empted transitions self-terminate on start.)
The suggested workaround in D3 3.x is to create a no-op, zero-delay transition after interrupting:
selection
.interrupt() // interrupt the active transition
.transition(); // pre-empt any scheduled transitions
That mostly works. But you can cheat it by scheduling another transition:
selection
.transition()
.each("start", alert); // 🌶
selection
.interrupt()
.transition();
Since the first transition isn’t yet active, it’s not interrupted. And since the second transition is scheduled after the first transition, the first transition is allowed to start before it is subsequently interrupted.
In D3 4.0, selection.interrupt both interrupts the active transition, if any, and cancels all scheduled transitions. Cancellation is stronger the pre-emption: the scheduled transitions are immediately destroyed, freeing up resources, and guaranteeing they won’t start.
selection.interrupt();
Maxim 6. Consider all possible usage patterns.
Asynchronous programming is notoriously difficult because the order of operations is highly unpredictable. While it is hard to implement robust and deterministic asynchronous APIs, surely it is harder to use brittle ones. The designer is responsible for being “thorough down to the last detail.”
Case 7. Naming parameters.
I’ll end with an easy one. D3 4.0 includes a few syntax improvements intended to make code more readable and self-describing. Consider this code using D3 3.x:
selection.transition()
.duration(750)
.ease("elastic-out", 1, 0.3);
Some questions you may have:
- What does the value 1 mean?
- What does the value 0.3 mean?
- What easing types besides “elastic-out” are supported?
- Can I implement a custom easing function?
Now compare to D3 4.0:
selection.transition()
.duration(750)
.ease(d3.easeElasticOut
.amplitude(1)
.period(0.3));
The meaning of 1 and 0.3 is now apparent, or at least you can now look up amplitude and period for elastic easing in the API reference, which helpfully includes this image:

Furthermore, there’s no longer a hard-coded set of easing names known by transition.ease; easing is always defined by a function. D3 4.0 still provides built-in easing functions, but hopefully it’s more obvious that you can roll your own custom easing function, too.
Maxim 7. Give hints.
Functions that take many arguments are obviously bad design. Humans shouldn’t be expected to memorize such elaborate definitions. (I can’t tell you how many times I’ve had to look up the arguments to context.arc when drawing to a 2D canvas.)
Since inception, D3 has favored named properties, using method chaining and single-argument getter-setter methods. But there’s still room for improvement. If code can’t be completely self-explanatory, at least it can point you to the right place in the documentation.
What Is The Purpose of Good Software?
It’s not just about computing a result quickly and correctly. It’s not even just about concise or elegant notation.
Humans have powerful but limited cognitive capacity. Many actors compete for that capacity, such as small children. Most importantly, humans learn. I hope my examples showed how the design of programming interfaces has a strong effect on whether humans can understand code and by extension whether they can learn to be proficient.
But learning goes beyond proficiency with a given tool. If you can take what you learn in one domain and apply it to other domains, that knowledge is much more valuable. That’s why, for instance, D3 uses the standard document object model and not a specialized representation. A specialized representation could perhaps be more efficient, but in the future when tools change, time you spent acquiring specialized knowledge may be wasted!
I don’t want you to learn D3 for the sake of D3. I want you to learn how to explore data and communicate insights effectively.
Good software is approachable. It can be understood completely in independent, easy pieces. You don’t need to understand everything before you can understand anything.
Good software is consistent. It lets you take what you’ve learned about one part and extrapolate it to the rest. It doesn’t self-contradict. It is parsimonious, avoiding superfluous elements.
Good software explains itself. It has affordances for learning and discovery. It is role-expressive and minimizes hidden magic.
Good software teaches. It doesn’t just automate an existing task, but provides insight or imparts knowledge, such as a best practice or a new perspective on a problem.
Good software is for humans. It is cognizant of people and the reality in which they live. It does not expect elaborate and arbitrary rules to be memorized. It anticipates the need for learning and debugging.