
index.md 17KB
title: The Web After Tomorrow
url: http://tonsky.me/blog/the-web-after-tomorrow/
hash_url: 34a79c7f0c
Modern web does a good job of bringing you live, real-time web applications. Or does it? This post looks at what is missing from the current state-of-the-art web architectures, where they should be improved and what tools we have at hand for that.
Server not required
Traditional web architectures require DB, server and a browser, stitched together with RPC and REST calls:
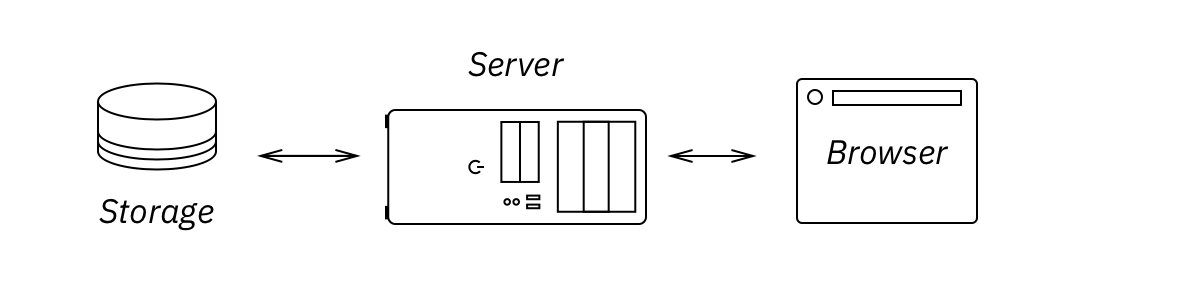
But today’s JS is good at doing almost anything we traditionally expect from a server. JS can handle view logic (better than server ever could), JS has no problem talking to the DB, executing queries and parsing result sets.
You probably had this feeling already, when you write server code only to proxy client’s demands for the DB and pass the results back. It feels stupid. It feels redundant. All these trends — isomorphic code, compile-to-js languages, node.js — come from a desire to run the same code in two places. That very goal is wrong. You don’t want to run same code in two places. You may need to, but only to deal with the consequences of bad (old) architecture. Running exactly the same validation twice wouldn’t make data more valid.
UI apps used to talk directly to the DB. Then thin client was introduced; to support that, intermediate smart proxy, or server, was added to the web stack. Today clients are thick again, but we keep putting server in the middle. Just out of habit.
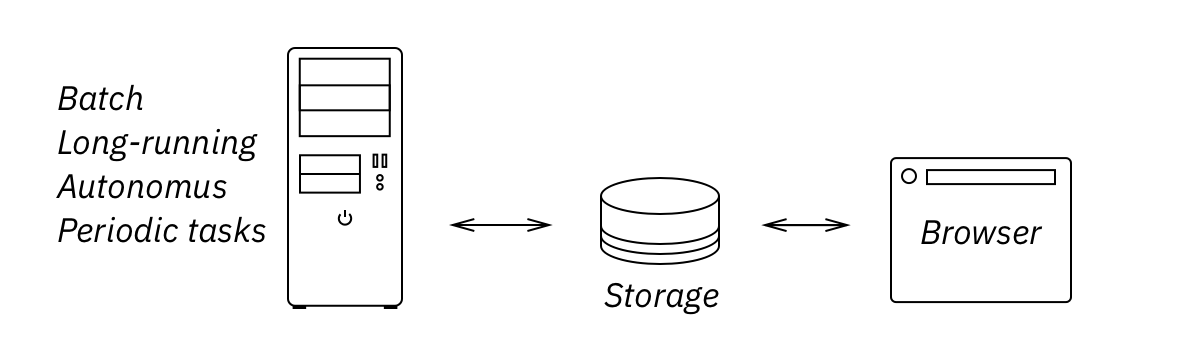
No, eventually DB will talk directly to the browser. Software may not be there yet, but it’s a matter of time. Until then, remember: it’s the server that is a generic component now, not the browser. Client logic is in control. JS gives orders, server/DB follows them.
Always late
Even though we can get rid of the server and handle everything in a browser, we’ll still be in the era of an ad-hoc, inconsistent, always-late web apps.
Take a look at the main Facebook page:
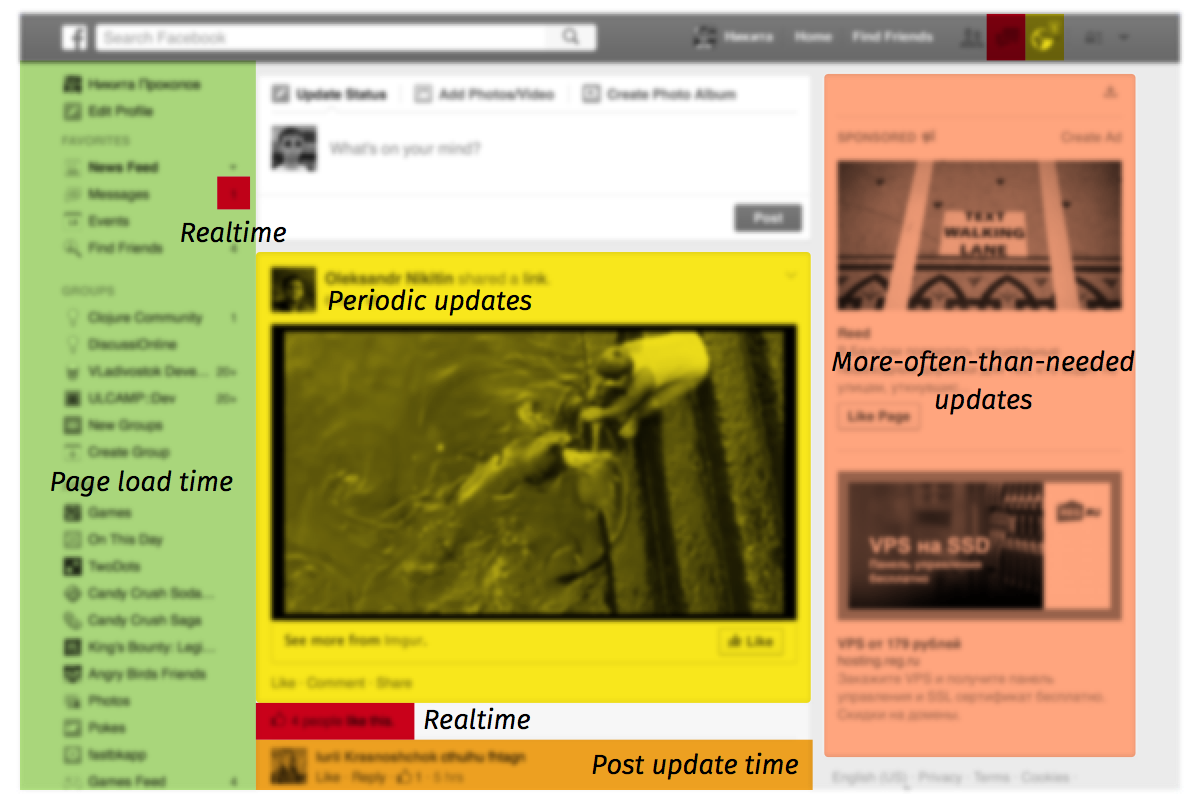
If you keep this page open for a couple of minutes, you’ll notice that different parts of it have different age. Some are static, they never update unless you refresh the page. Some are updated almost instantly. Some are refreshed periodically. Even when you look at the same data piece (e.g. user name) across the page, it can look different in different places, depending on how long ago the component containing it was last updated. Facebook is a modern, cutting-edge web app, but even it is not real-time enough. Every Facebook page is stale and inconsistent almost all the time except for the couple of seconds right after page load. This is not about Facebook, of course, every other page of every other web application is stale, too. Despite the buzz, the real-time web has not landed yet.
Some may argue if that needs to be fixed at all. I’m OK to refresh page once in a while. I don’t change user name that often. We love Facebook for the people and can bear couple of technology quirks.
I agree. For vast majority of people, it might be not the most pressing problem at the moment. But what people are used to is always a bad measure. If people have learned to adapt to something does not imply we should stop looking for improvements. Looking into crazy and seems-to-be-unreachable places might still give us useful insights.
Web technology stack was created under assumption that people are looking at rarely-changing, mostly static data. Generally it does a decent job of loading missing data pieces as you go. Throw in AJAX/WebSockets and periodical updates and best you’ll get is a web page stitched from the pieces of data at different stages of staleness. It’s expected. This result comes naturally from using HTTP, JS, SQL, REST the most natural way. To get beyond that, we need to forget what we’ve learned about them. We need to avoid short and well-known paths. We should not fear to do the unnatural things.
What we actually want is not even a request-response protocol. At the high level we want to connect data source and a client as tight as possible, with the library taking care of all the negotiation details. These are the things we are interested in:
-
Consistent view of the data. What we’re looking at should be coherent at some point-in-time moment. We don’t want patchwork of static data at one place, slightly stale at another and fresh rare pieces all over the place. People percieve page as a whole, all at once. Consistency removes any possibility for contradictions in what people see, consistent app looks sane and builds trust.
-
Always fresh data. All data we see on the client should be relevant right now. Everything up to the tiniest detail. Ideally including all resources and even code that runs the app. If I upload a new userpic, I want it to be reloaded on all the screens where people might be seeing it at the moment. Even if it’s displayed in a one-second-long, self-disposing notification popup.
-
Instant response. UI should not wait until server confirms user’s actions. Effect of the action should be displayed immediately.
-
Handle network failures. Networks are not a reliable communication device, yet reliable protocols can be built on top of them. Network failures, lost packets, dropped connections, duplicates should not undermine our consistency guarantees.
-
Offline. Obviously data will not be up-to-date, but at least I should be able to do local modifications, then merge changes when I get back online.
-
No low-level connection management, retries, deduplication. These are tedious, error-prone details with subtle nuances. App developers should not handle these manually: they will always choose what’s easier or faster to implement, sacrificing user experience. Underlying library should take care of the details.
These are all worthy goals irrespective of their technical feasibility. In the coming decades we might have, and we might have not see some of them studied, implemented or even becoming industry standard. We’ll probably see many failed and (I hope) some successful attempts to approach them. Nevertheless, the goals will stay the same.
The rest of this post is a speculation on where to start the quest for the Holy Grail of the Web. I don’t have all the answers. And (spoiler alert) I don’t know how to make Facebook straight-out real-time. But we have to start somewhere.
The Quest for the Holy Grail of the Web
This is the high-level overview of the problem as I see it:
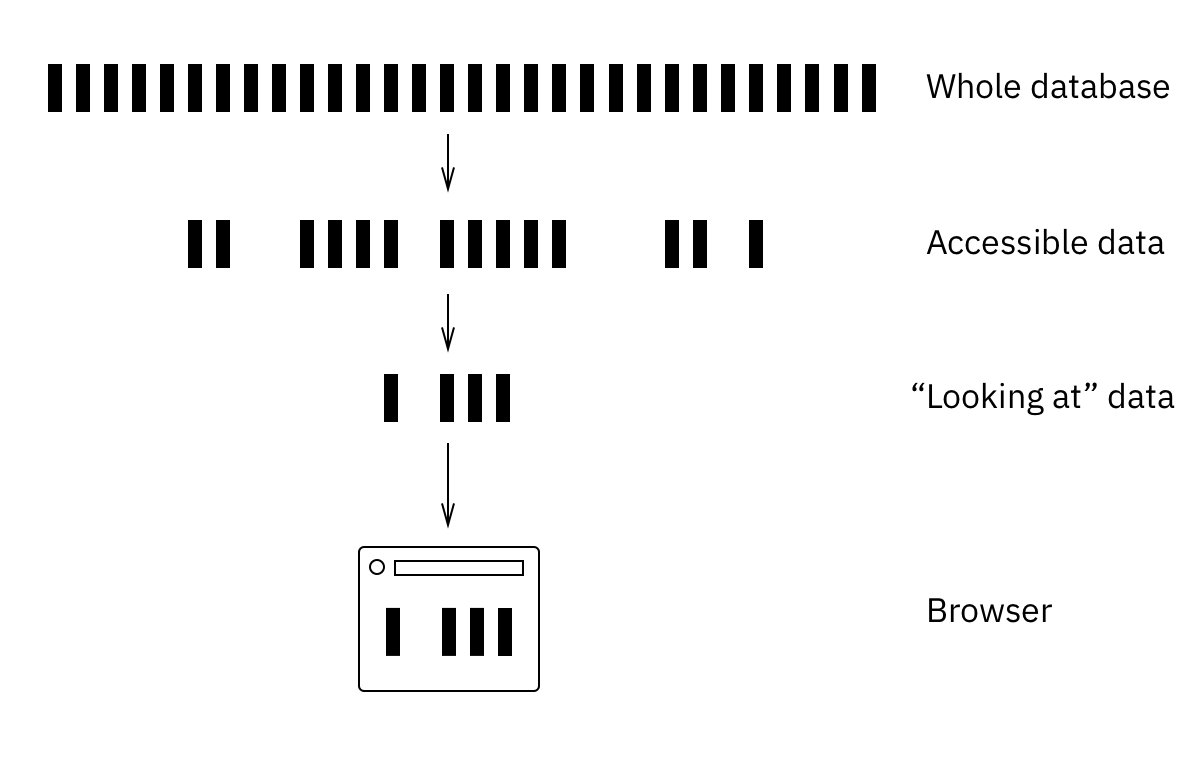
The big data source on the top is all the data we have in the project. Before reaching the client, it must come through two filters. First one is a security filter. It filters out all the data user is not authorized to see, leaving out just personal, shared and public rows. The second filter leaves only the parts user is interested in. For UI it means parts which are required to render current page.
Everything that passes these two filters should be pushed to the client instantly, in real time. It is, by definition, everything client needs to render a page.
There are two tricks here. First one is efficiency. Web pages are usually pretty complex, they may track hundreds of different objects, they may track results of complex queries, they may track aggregations. And we might have thousands of live clients connected at the same time.
This is the most unexplored part of the Future Web landscape. You’re probably used to describe data needs in terms of queries. Query is a recipe to get the data from the storage. To get real-time, we need these queries to work the other way around. Client still defines its needs via query. This query might be used for initial data fetch, just as usual. The same query will then be used to filter whole-DB changelog and decide what parts of it server should push to which client. Fetch is about trying to get the data given the query. Push is about finding the affected subscriptions given the changed data.
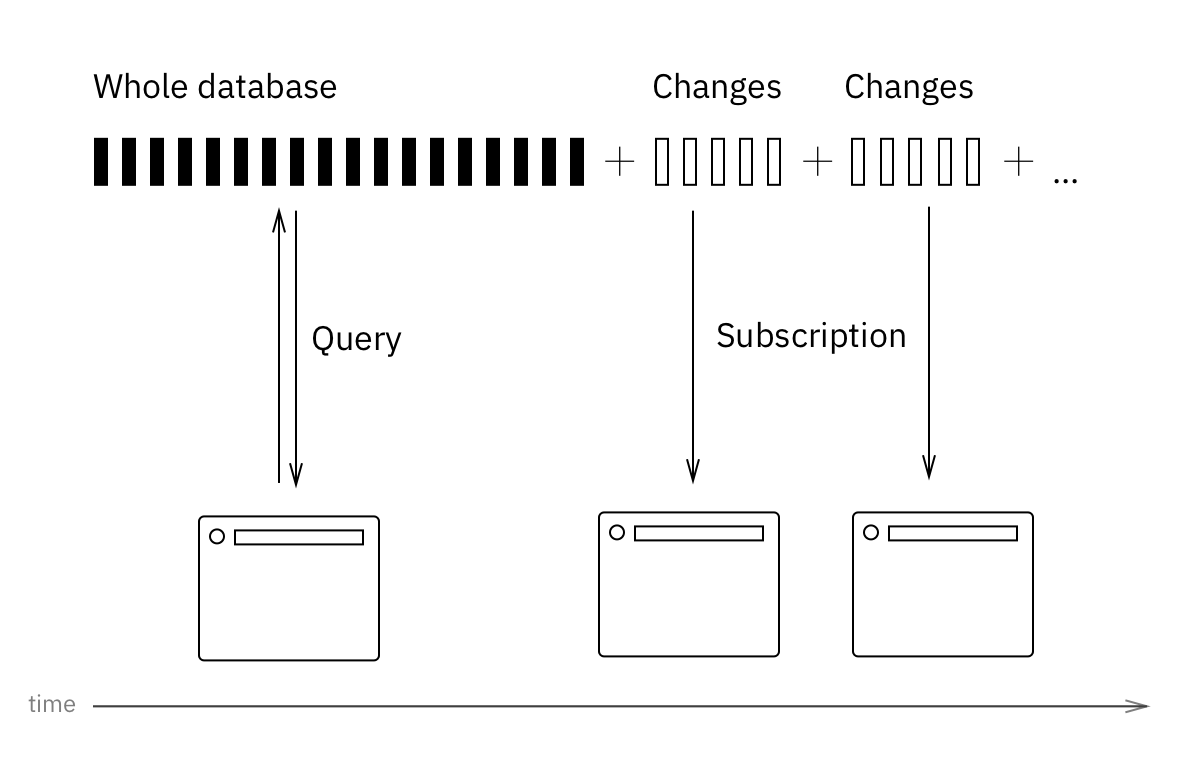
What we need here is probably a new query language, something like reversible SQL. We need our hypothetical ReversibleQL to run efficiently in both directions. To get these properties, ReversibleQL would probably have to be much simpler and more limiting than SQL. Or it might be two different languages. I don’t know. Meteor.js solves this problem by limiting subscriptions to documents and collections only. RethinkDB folks are trying to build transparently reversible queries, but they aren’t very chatty about internal details. I used to work in a startup that delivered real-time query results to power comments for ESPN, WWE, CNN, Scripps and Washington Post. I wouldn’t say it was a walk in the park, we had to build a custom infrastructure for that, but it was certainly doable on a scale of 50K RPS and varied, user-specified, non-trivial queries. We just need something open-source like that.
The second catch is that filters and subscriptions change over time. This is not a performance problem (usually), but more of an organizational one. How do you track subscriptions? How to detect dead ones and how to collect garbage? On a client we can benefit from a insufficiently praised React feature: component lifecycles. By listening for didMount and willUnmount we can reliably track when components (and their subscriptions) come and go. That way we always know exactly what our visitor is looking at. On a server, though, it’s just timeouts, refcounting, periodic cleaning and careful coding. No rocket science here.
While we’re still in “DB to client” data flow, let’s talk reliability. Real-time is fine, but reliable real-time is even finer. There’s little point in pushing data changes if you can underdeliver some of them: the outcome wouldn’t be that great without consistency. A single DELETE lost from changefeed during reconnect (with no integrity validation) might lead to the catastrophic UI glitches. Reordering is out of question too, for the same reasons. This is a territory of distributed databases here, where browser plays the role of one of the peers. For example, DB could provide a strongly consistent event log, and DB-client synchronization protocol can take advantage of that. Or we might choose eventual consistency, CRDTs and anti-entropy measures. Anyway, distributed computing is pretty crowded these days, let’s assume we know how to do it well. Browser is not traditionally viewed as a peer (CouchDB is moving in that direction though), but in fact it doesn’t change a thing. Only this time netsplits are more than real — they are everyday routine.
Now we’ve talked about listening for the changes, but not about initiating them. Of course, every local action should be captured, transformed into a change/delta, put into some sort of a queue and sent to the server in the background. Easy even with the current web stack.
Missing spots here are lag compensation and offline work. Nothing beats unresponsive input in the amount of annoyance and frustration it causes. The Net is so slow we should compensate for the roundtrip even if person is online and has a good connection. That’s why we display effects of all user actions immediately, before sending them to the server.
Offline is a special case of lag compensation where lag is infinite. Offline mode should look just like a normal app without real-time updates. No need to treat it any different: we just embrace that deltas queue could grow indefinitely and make process of making local changes sustainable.
Centralized, application-wide state management is crucial here. I cannot imagine how something like this could be implemented ad-hoc, on a per-variable basis. But if you treat all your app state like some kind of storage (e.g. Relay storage, nested immutable dictionary or DataScript DB), you can implement synchronization on a system level. You would also need explicit change management to send deltas over network, track them, conserve in local storage and apply them to the local state.
Pragmatic disenchantment
This is more of a “get you into the right mode of thinking” post. I don’t know any apps based on such architecture, I don’t even have a proof-of-concept example. There’s no ready-made framework to take off the shelf. Two years ago you would even have had a bad time assembling such a thing by yourself because there were no software with required properties.
These days it’s not that grim though:
-
We have RethinkDB aiming at the same goal, but lacking client-side storage and reliable pushes.
-
We have Relay which has local storage and lag compensation, but no real-time pushes from the server (they are thinking about adding them in the future).
-
Meteor.js gets closer of them all: it solves discussed problem for a simple case of small unordered collections of JSON documents. It has latency compensation, local storage, server push, subscriptions, server data filtering. I can’t find any information about consistency and reliability guarantees of their DDP protocol or how well server push scales with the number of subscriptions.
I personally see a great opportunity in using Clojure, Datomic and DataScript to build such a system:
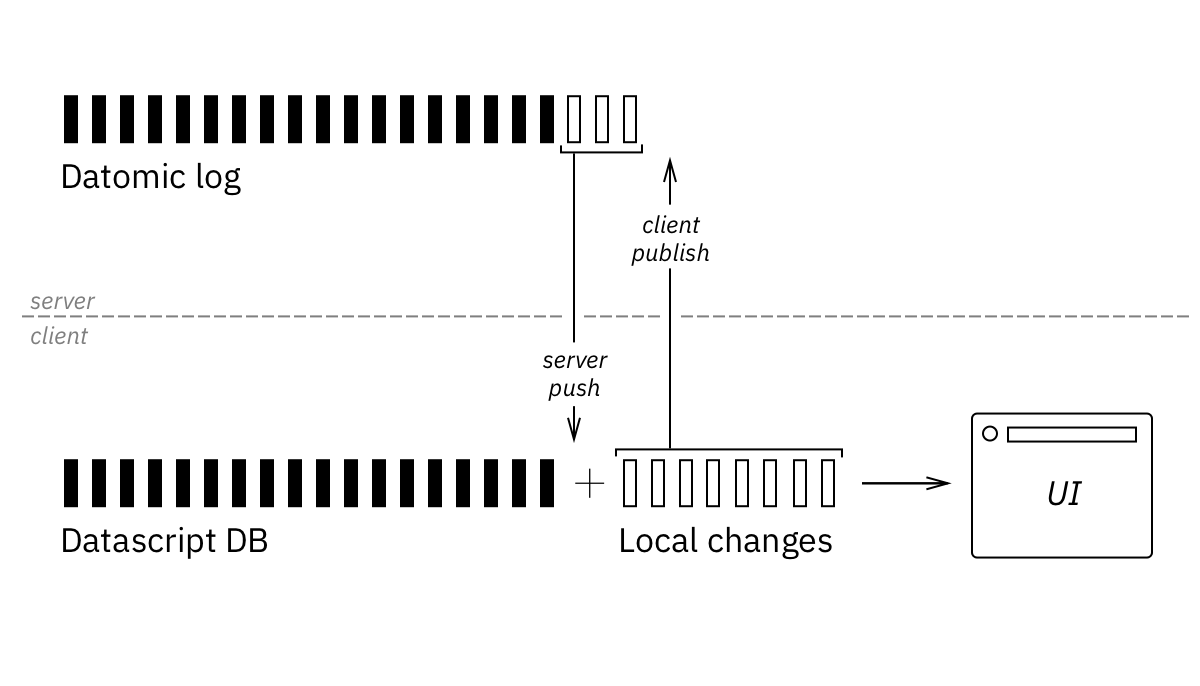
-
Datomic is a general-purpose DB which also maintains a log of all transactions. Monotonic transaction ids make reliable syncing an easy task (log replication).
-
Datomic has reactive transactions queue which is part of a public API, meaning efficient reactive pushes without polling or replication log parsing.
-
Datomic has RDF-like data model (datom = entity, attribute, value) which is at a great granularity level for security and subscription filters. Datom is the smallest piece of information that could be synchronized, and that’s exactly what Datomic DB is made of.
-
On a client we have DataScript which mimics Datomic API, so essentially it’s the same database, with the same data model, and the two work very well together.
-
Datomic and DataScript have serializable transaction format, no need to invent anything ad-hoc to represent the deltas.
-
DataScript is immutable, meaning we can keep local changes, apply/retract them, reorder, throw away and build temporary local databases on the fly. This property is very basic for DataScript because of its immutable nature, meaning there are no hidden limitations or partial support for some sort of changes.
-
Reactive UI is simple over DataScript with top-down React render. If your UI is big and complex and needs granular updates based on what have changed in a DB, it’s also pretty straightforward, although there is no ready-made library for that at the moment.
-
Subscription language is the biggest missing piece of this stack. Datomic and DataScript speak Datalog which is very powerful language, but it is hard to reverse efficiently. If you have very high volume of the transactions going through your DB, for each of them you’ll have to determine which clients should get an update. Running a Datalog query per client is not an option.
Conclusion
The web is only as good as current generation of tools for building it are. The right tools come from the right goals. As I see it, eventually web will work by the fully reactive principles. This post lays out the map of unsolved problems and discusses possible approaches to them.