
index.md 19KB
title: Agility Requires Safety
url: http://www.themacro.com/articles/2016/03/agility-requires-safety/
hash_url: 21c99b5469
Imagine it’s your job to get all the cars on a highway to drive faster. What would happen if you just told all the drivers to wildly jam down on their gas pedals?
Clearly, the result would be a disaster. And yet, this is exactly the kind of attitude many developers take with trying to build software faster. Here are some of the reasons they use for why:
“We’re trying to be really agile, so we don’t waste time on design or documentation.”
“I have to ship this to production immediately, so I don’t have time to write tests!”
“We didn’t have time to automate everything, so we just deploy our code by hand.”
For cars on a highway, high-speed driving requires safety. In order to drive a car faster, you need safety mechanisms such as brakes, seat belts, and airbags that ensure the driver will be unharmed in case something goes wrong.
For software, agility requires safety. There is a difference between making intelligent tradeoffs and throwing all caution to the wind and charging blindly ahead. You need safety mechanisms that ensure those changes cannot do too much damage in case something goes wrong. If you’re reckless, you will ultimately move slower, not faster:
That one hour you “saved” by not writing tests will cost you five hours of tracking down a nasty bug in production, and five hours more when your “hotfix” causes a new bug.
Instead of spending thirty minutes writing documentation, you’ll spend an hour training each co-worker how to use your code, and hours more cleaning things up when they use it incorrectly.
You might have saved a little time by not setting up automation, you’ll waste far more time repeatedly deploying code by hand, and even more time tracking down bugs when you accidentally miss a step.
What are the key safety mechanisms of the software world? In this post, I’ll discuss three safety mechanisms from the physical world and the analogous safety mechanisms from the software world:
Brakes / Continuous Integration
In a car, good brakes stop your car before you run into a problem. In software, continuous integration stops buggy code before it goes into production. To understand continuous integration, let’s first talk about its opposite: late integration.
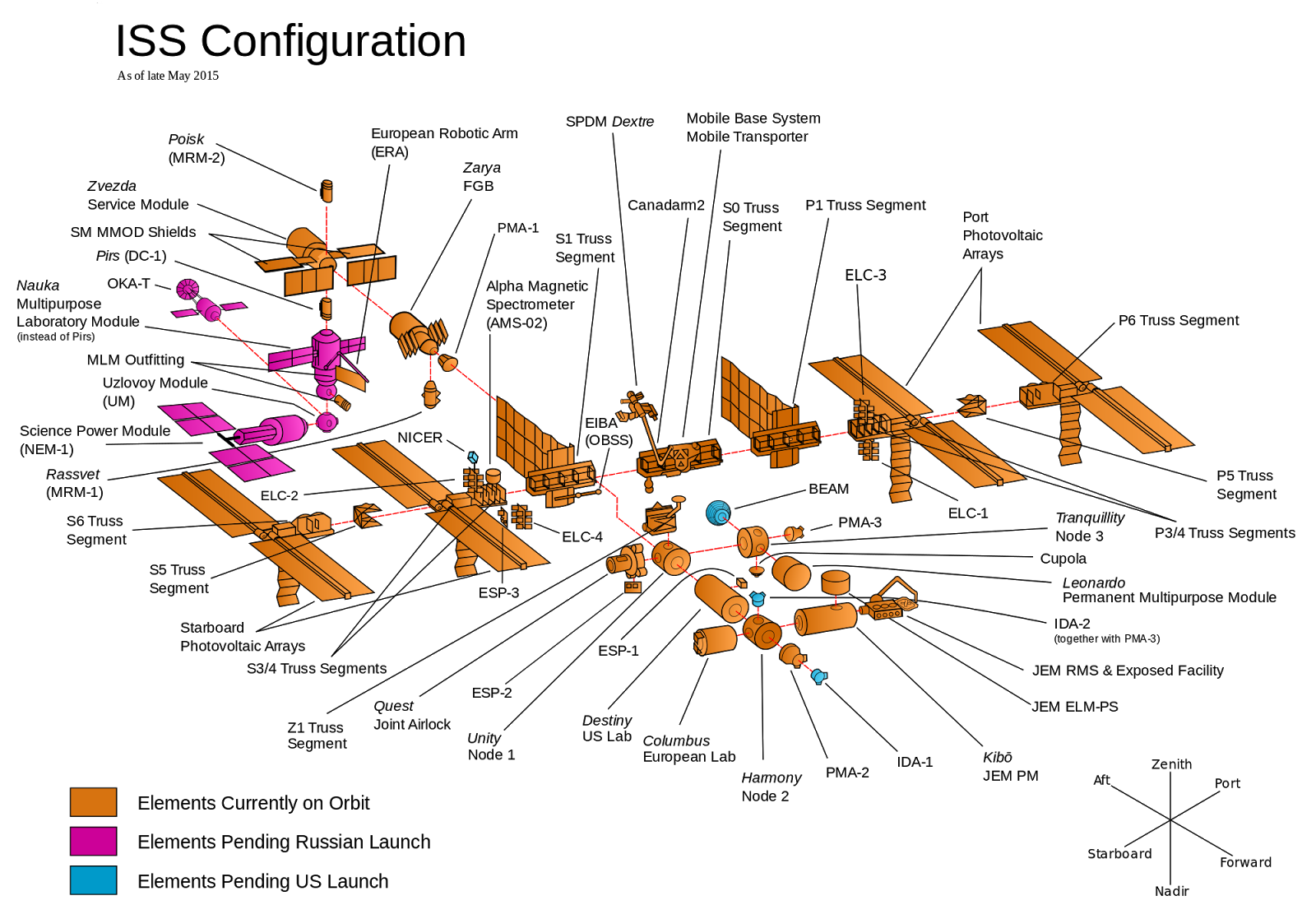
Imagine you’re responsible for building the International Space Station (ISS), which consists of dozens of components, as shown in Figure 1. A team from a different country will build each component, and it’s up to you to decide how you will organize them. You have two options:
Come up with a design for all the components up front, and then have each team go off and work on their component in total isolation. When all the teams are done, you’ll launch all the components into outer space, and try to put them together at the same time.
Come up with an initial design for all the components and then have each team go off and start working. As they make progress, they continuously test each component with all the other components and update the design if there are any problems. As components are completed, you launch them one at a time into outer space, and assemble them incrementally.
With option #1, attempting to assemble the entire ISS at the last minute will expose a vast number of conflicts and design problems: The German team would think the French team would handle the wiring, while the French would think the British would do it; all the teams would use the metric system, except one; no one would prioritize installing a toilet. Finding all of this out once everything has already been built and is floating in outer space means that fixing the problems will be very difficult and expensive.
Unfortunately, this is exactly the way in which many companies build software. Developers work in total isolation for weeks or months at a time on feature branches and then try to merge all their work together into a release branch at the very last minute. This process is known as late integration, and it often results in days or weeks wasted on fixing merge conflicts (as shown in Figure 2), tracking down subtle bugs, and trying to stabilize release branches.
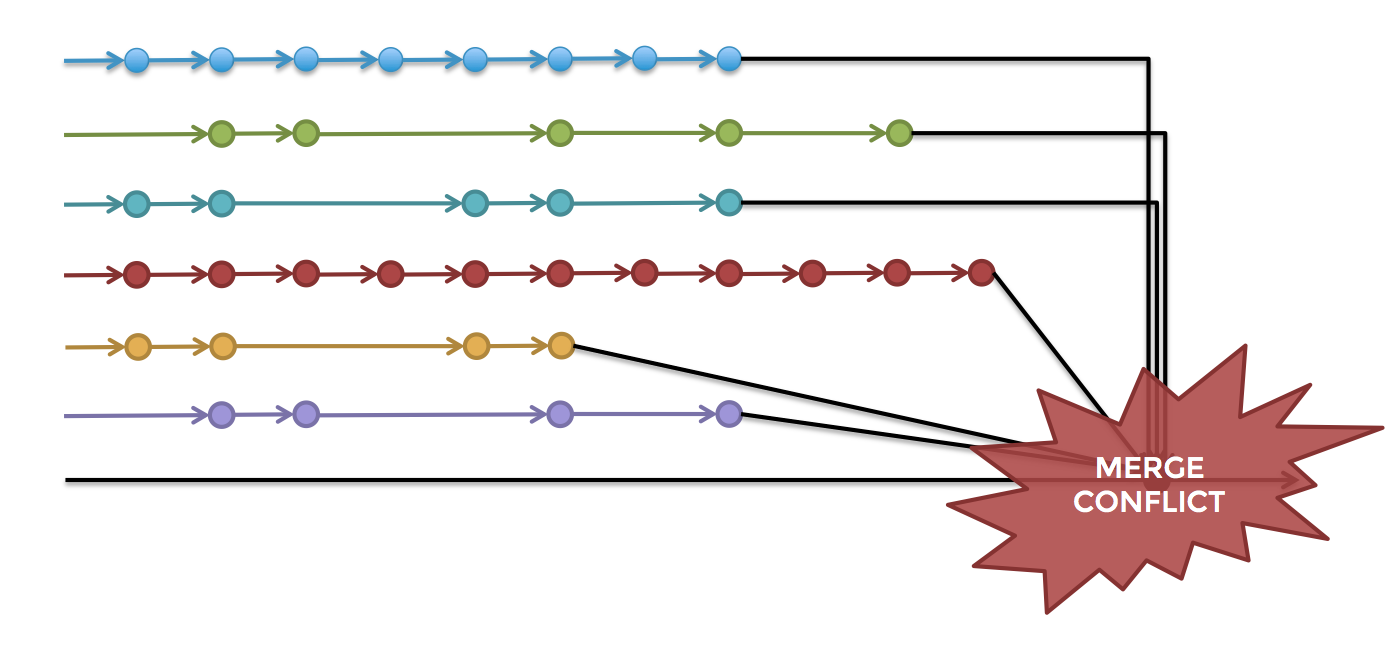
An alternative approach, as described in option #2 above, is continuous integration, where all developers merge their work together on a very regular basis. This exposes problems with the design earlier in the process before you’ve gone too far in the wrong direction, and allows you to improve the design incrementally. The most common way to implement continuous integration is to use a trunk-based development model.
In a trunk-based development model, developers do all of their work on the same branch, called trunk or master, depending on the Version Control System (VCS). The idea is everyone regularly checks into this branch, perhaps even multiple times per day. Can having all developers work on a single branch really scale? Trunk-based development is used by the thousands of developers at LinkedIn, Facebook, and Google. Google’s trunk statistics are particularly impressive: they manage over 2 billion lines of code and 45 thousand commits per day on a single branch.

How can thousands of developers frequently check into the same branch without conflicts? It turns out that if you make small, frequent commits instead of huge monolithic merges, the number of conflicts is fairly small and those that do happen are desirable. That’s because you’ll have to deal with conflicts no matter what integration strategy you use, and it’s easier to deal with a conflict representing one or two days of work (with continuous integration), rather than a conflict representing months of work (with late integration).
What about branch stability? If all developers are working on the same branch, and one developer checks in code that doesn’t compile or causes serious bugs, it could block all development. To prevent this, you must have a self-testing build. A self-testing build is a fully automated build process (i.e., you can run it with a single command) that has enough automated tests so that, if they all pass, you can be confident the code is stable. The usual approach is to add a commit hook to your Version Control System that takes each commit, runs it through the build on a continuous-integration (CI) server such as Jenkins or Travis, and rejects the commit if the build fails. The CI server is your gate keeper, validating every check-in before allowing it into trunk, and acting as a good set of brakes that stops bad code before it gets to production.
Without continuous integration, your software is broken until somebody proves it works, usually during a testing or integration stage. With continuous integration, your software is proven to work (assuming a sufficiently comprehensive set of automated tests) with every new change—and you know the moment it breaks and can fix it immediately.
-- Jez Humble and David Farley, Continuous Delivery
How can you use continuous integration to make large changes? That is, if you are working on a feature that takes weeks, how can you check into trunk multiple times per day? One solution is to use feature toggles.
Safety Catches / Feature Toggles
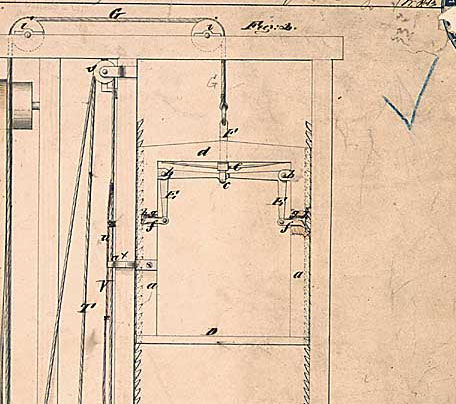
In the early 19th century, most people avoided elevators, fearing that if the cable snapped, the elevator and its inhabitants would plunge to their death. To solve this problem, Elisha Otis invented the “safety elevator” as well as a daring demonstration of its effectiveness. For the demonstration, Otis built a large open elevator shaft, hoisted an open elevator up several stories, and in front of a live audience, would have an assistant cut the elevator cable, as shown in Figure 4. The elevator would fall, briefly, and then come to an immediate stop.

How did it work? The key to the safety elevator is the safety catch, which you can see in Figure 5. By default, the safety catches are fully extended so that they hook onto the latches in the elevator shaft and prevent the elevator from moving. The only way to retract the safety catches is if the elevator cable is taut enough to pull the catches in. In other words, the catches only disengage if the cable is intact.
In this brilliant design, the safety catches provide safety by default. In software, feature toggles provide safety by default. The way to use feature toggles is to wrap all new code in an if-statement that looks up a named feature toggle (e.g. showFeatureXYZ) from a configuration file or a database.
if (featureToggleEnabled(“showFeatureXYZ”)) {
showFeatureXYZ()
}
The key idea is that, by default, all feature toggles are off. That is, the default is safe. That means that you can check in and even deploy code that’s unfinished or buggy, so long as it’s wrapped in a feature toggle, as the if-statement will ensure that code won’t be executed or have any visible impact.
When the feature is completed, you can turn on that named feature toggle. The simplest way is to store named feature toggles and their values in config files. That way, you could enable the feature in the development environment config, but disable it in production, until it’s ready.
# config.yml dev:showFeatureXYZ: trueprod:
showFeatureXYZ: false
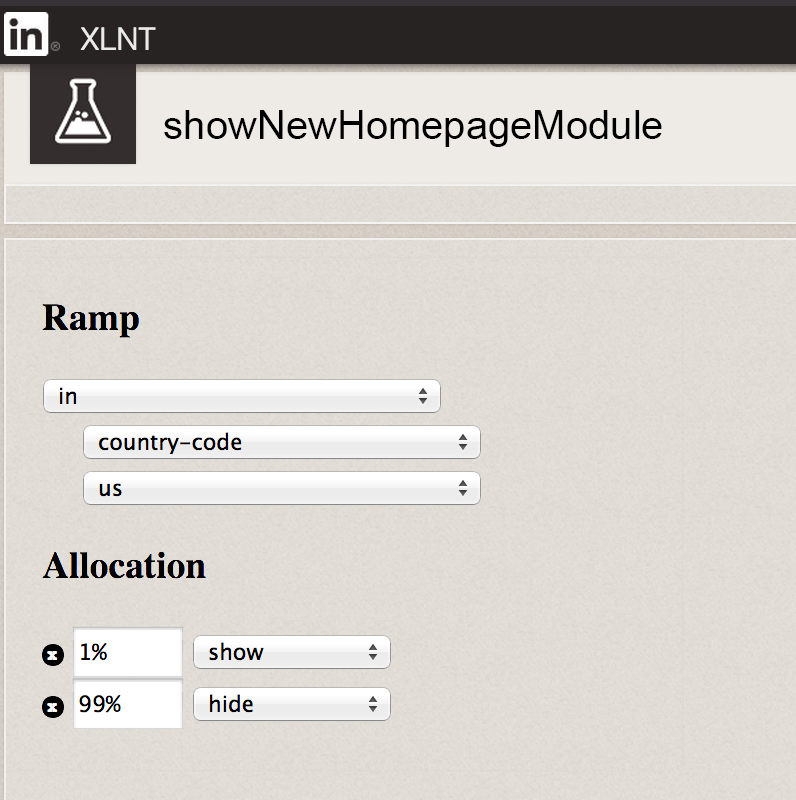
A more powerful option is to have a dynamic system that can determine the value of a feature toggle for each user and a web UI where your employees can dynamically change feature toggle values to enable or disable features for certain users, as shown in Figure 6.
For example, during development, you could initially enable the feature toggle just for employees of your company. When the feature is done, you can enable it for 1% of all users. If things look good, you ramp it up to 10% of users, then 50% of users, and so on. If at any point there is a problem, you just use the web UI to disable the feature. You can even use feature toggles for A/B testing or bucket testing.
Bulkheads / Splitting up the Codebase
In a ship, you use bulkheads to create isolated, watertight compartments. This is so that if there is a hull breach, flooding is contained within a single compartment.
Similarly, in software you can split up the codebase into isolated components, so if there is a problem, it is contained within a single component.
Splitting up a codebase is important because the worst thing that can happen to a codebase is excess size. The more code you have, the slower you go. For example, consider the following chart from Code Complete, which shows project size (lines of code) versus bug density (number of bugs per thousand lines of code):
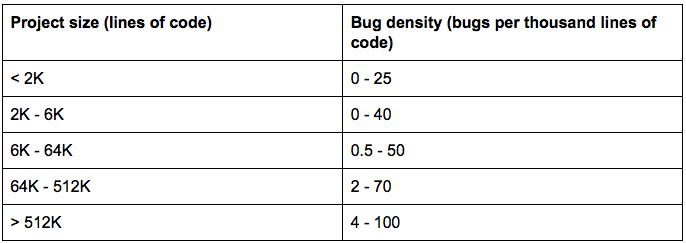
What this means is that as your codebase grows, the number of bugs grows even faster. If your codebase grows by a factor of 2, the number of bugs in it could grow by a factor of 4 or 8. And by the time you’re working with more than half a million lines of code, bug rates can be as high as one bug for every 10 lines of code!
The reason for this, to borrow a quote from Practices of an Agile Developer, is that “software development doesn’t happen in a chart, an IDE, or a design tool; it happens in your head.” A codebase with hundreds of thousands of lines of code is far beyond what you can fit in your head. You can’t consider all the interactions and corner cases in that much code. Therefore, you need strategies for splitting up the code so that you can focus on one part at a time and safely ignore the rest.
There are two main strategies for breaking up a code base: one is to move to artifact dependencies, and the other is to move to a microservice architecture.
The idea behind artifact dependencies is to change your modules so that instead of depending on the source code of other modules (source dependencies), they depend on versioned artifacts published by other modules (artifact dependencies). You probably do this already with open source libraries. To use jQuery in your JavaScript code or Apache Kafka in your Java code, you don’t depend on the source code of those open source libraries, but on a versioned artifact they provide, such as jquery-1.11-min.js or kafka-clients-0.8.1.jar. If you use a fixed version of each module, the changes developers make in those modules will have no effect on you until you explicitly choose to upgrade. Like bulkheads, this isolates you from problems in other components.
The idea behind microservices is to move from a single monolithic app, where all your modules run in the same process and communicate via function calls, to isolated services, where each module runs in a separate process, usually on a separate server, and they communicate with each other via messages. Service boundaries work well as code ownership boundaries, so microservices can be a great way to allow teams to work independently from one another. Microservices also allow you to use a variety of technologies to build your products (e.g. one microservice could be in Python, another in Java, another in Ruby) and to scale each service independently.
Although artifact dependencies and microservices offer a lot of benefits, they also come with many significant drawbacks, not the least of which is they both run counter to the Continuous Integration ideas you saw earlier. For a full discussion of the tradeoffs, check out Splitting Up a Codebase into Microservices and Artifacts.
The three questions
While safety mechanisms allow you to go faster, they are not free. They require an upfront investment, during which you may actually move slower. So how do you decide how much time to invest in a safety mechanism versus the actual product? To make this decision, you have to ask three questions:
To wrap up this post, let’s see how the three questions above play out for a common decision: Whether or not to do automated testing.
Although some die-hard testing enthusiasts argue that you must write tests for everything and aim for 100% code coverage, it’s exceedingly rare to see anything close to that in the real world. While writing my book Hello, Startup, I interviewed developers from some of the most successful startups of the last decade, including Google, Facebook, LinkedIn, Twitter, Instagram, Stripe, and GitHub. I found that they all made very deliberate tradeoffs about what to test, and what not to test, especially in their early days.
Let’s go through the three questions:
What is the cost of writing and maintaining automated tests?
Setting up unit tests these days is cheap. There are high-quality unit testing frameworks for almost every programming language, most build systems have built-in support for unit testing, and they typically run quickly. On the other hand, integration tests (especially UI tests) require running large parts of your system, which means they are more expensive to set up, slower to run, and harder to maintain.
Of course, integration tests can catch many bugs that unit tests can’t. But because they cost so much more to set up and run, I’ve found that most startups invest in a large suite of unit tests and but only a small suite of highly valuable and critical integration tests.
What is the cost of the bugs that slip by if you don’t have automated tests?
If you’re building a prototype that you’ll most likely throw away in a week, the cost of bugs is low, so it may not pay off to invest in tests. On the other hand, if you’re building a payment processing system, the cost of bugs is very high: You don’t want to charge a customer’s credit card twice, or for the wrong amount.
Although the startups I talked to varied in their testing practices, just about every single one identified a few parts of their code -- typically payments, security, and data storage -- that were simply not allowed to break, and therefore were heavily tested from day one.
How likely are you to have bugs without automated tests?
As we discussed earlier, when a codebase grows, the number of bugs grows even faster. The same thing happens as the size of your team grows and as the complexity of what you’re building increases.
A team of two developers with 10,000 lines of code might spend only 10% of their time writing tests; a team of twenty developers with 100,000 lines of code may have to spend 20% of their time writing tests; and a team of two hundred developers with 1 million lines of code may have to spend 50% of their time writing tests.
As the number of lines of code and developers increases, you have to invest proportionally more and more of your time into testing.