
NdT : Depuis 2 ans, notre équipe utilise Gitflow, un modèle de développement simple, documenté dans cet article. Cette convention facilite entre autres le déploiement continu. Nous vous encourageons à l’adopter à votre tour.
Nous avons donc traduit l’article original de Vincent Driessen à destination des équipes agiles francophones.
Dans cet article je présente le modèle de développement que j’ai commencé à utiliser pour tous mes projets (professionnels et personnels) depuis 1 an, et qui s’est avéré être très efficace. Cela fait un moment que je voulais écrire à son propos, mais je n’avais pas vraiment tout à fait pris le temps de le faire, jusqu’à maintenant. Je ne vais pas parler des détails des projets, simplement de la stratégie de ramification des branches et de la gestion des versions.
C’est axé autour de Git comme outil de versionnement pour tout le code source.
Pour une discussion approfondie sur les avantages et les inconvénients de Git comparé à des systèmes centralisés de contrôle du code source, regardez sur le web. Il y a plein d’échanges de points de vue qui continuent sur le web.
En tant que développeur, je préfère Git à tous les autres outils qui existent aujourd’hui. Git a vraiment changé la manière dont les développeurs pensent la fusion et la bifurcation de branche. Dans le monde des classiques CVS/ Subversion d’où je viens, fusionner/ramifier a toujours été considéré comme quelque chose d’un peu effrayant (attention aux conflits après une fusion, ils mordent !) et c’est une opération qu’on ne fait que de temps à autre.
Mais avec Git, ces opérations sont très peu coûteuses et très simples et elles sont vraiment considérées comme partie intégrante de votre manière de travailler au quotidien. Par exemple dans les livres sur CVS/Subversion, la création de branche et la fusion ne sont évoquées que dans les derniers chapitres (pour les utilisateurs avancés), alors que dans n’importe quel livre sur Git, c’est un sujet couvert dès le chapitre 3 (les bases).
Grâce à sa simplicité et à sa nature répétitive, la bifurcation et la fusion ne sont plus une opération à redouter. Les outils de contrôle de version sont avant tout supposés aider dans la bifurcation/fusion.
Assez parlé des outils, voyons maintenant le modèle de développement. Le modèle que je présente ici n’est rien d’autre qu’un ensemble de procédures que chaque membre de l’équipe doit respecter pour parvenir à un processus de gestion de développement logiciel.
La configuration de dépôt que nous utilisons et qui marche bien avec ce modèle de développement, est celle avec un « vrai » dépôt central. Notez que ce dépôt est simplement considéré comme étant le dépôt central (puisque Git est un système de version décentralisé, techniquement il n’existe pas de dépôt central en tant que tel.). Nous ferons référence à ce dépôt comme origin, puisque tous les utilisateurs de Git sont familiers avec ce nom.
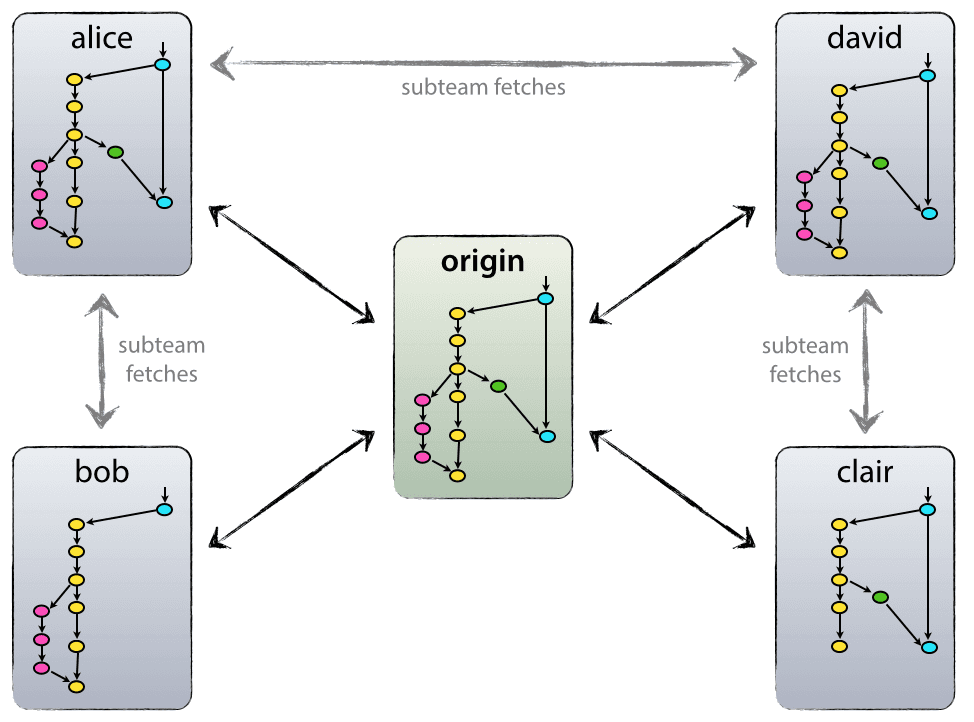
Chaque développeur pull et push sur origin. Mais au delà de la relation centralisée push-pull, chaque développeur peut aussi récupérer des changements d’autres équipiers et ainsi former des sous-équipes. Par exemple, cela peut s’avérer utile quand deux ou plusieurs développeurs travaillent ensemble sur une fonctionnalité, plutôt que de pousser prématurément le travail en cours sur origin. Dans l’illustration ci-dessus, il y a des sous-équipes d’Alice et Bob, Alice et David et Claire et David.
Techniquement, cela veut simplement dire qu’Alice a défini un dépôt distant, nommé bob, qui pointe vers le dépôt de Bob et inversement.
À la base, ce modèle de développement s’inspire fortement de modèles existants. Le dépôt central héberge les deux branches principales qui ont une durée de vie infinie :
La branche master sur origin devrait être connue des utilisateurs de Git. Parallèlement à la branche master, une autre branche appelée develop est présente.
Nous considérons origin/master comme étant la branche principale où le code source de HEAD reflète l’état de prêt pour être déployé en production.
Nous considérons origin/develop comme étant la branche principale où le code source de HEAD reflète les derniers changements livrés pour la prochaine version. Certains l’appelleraient « branche d’intégration ». C’est à partir de cet emplacement que sont compilées les versions quotidiennes.
Quand le code source dans la branche develop est considéré stable et prête à être livré, tous les changements doivent être fusionnés dans master puis se voient assignés d’un numéro de version. Nous verrons comment faire cela en détails plus loin.
En conséquence, à chaque fois que des changements sont reportés dans master, par définition c’est une nouvelle version de production. Nous devons être très strict avec ceci, pour qu’hypothétiquement nous puissions utiliser un hook Git afin de compiler et déployer automatiquement notre logiciel sur nos serveurs de production à chaque fois qu’il y a un commit sur master.
A côté des branches principales
master et
develop, notre modèle de développement utilise une variété de branches de support pour aider le développement en parallèle entre les membres de l’équipe, faciliter le suivi des fonctionnalités, préparer les versions de productions et nous aider à réparer rapidement les problèmes survenus en production.
Contrairement aux branches principales, ces branches ont toujours une durée de vie limitée, puisqu’elles seront effacées au final.
Les différents types de branches que nous pouvons utiliser sont :
Chacune de ces branches a un but précis et elles obéissent à des règles strictes comme de quelles branches elles peuvent provenir et dans quelles branches elles peuvent être fusionnées. Nous allons voir comment dans quelques minutes.
Ce ne sont en aucun cas des branches « spéciales » d’un point de vue technique. Les types de branche sont catégorisés par la façon dont nous les utilisons. Ce sont bien sûr de bonnes vieilles branches Git.
Les branches de fonctionnalités (parfois appelées branches de thème) sont utilisées pour développer de nouvelles fonctionnalités pour la prochaine version ou pour une future. Au début du développement d’une fonctionnalité, la version cible dans laquelle cette fonctionnalité sera ajoutée peut très bien être inconnue à cet instant. La raison d’être d’une branche de fonctionnalité est qu’elle existe tant que la fonctionnalité est en cours de développement, mais sera finalement fusionnée dans develop (pour ajouter la fonctionnalité à la prochaine version) ou abandonnée (dans le cas d’une expérience décevante).
Les branches de fonctionnalités n’existent typiquement que dans les dépôts des développeurs, pas sur origin.
Lorsque vous commencee à travailler sur une nouvelle fonctionnalité, partez de la branche develop
$ git checkout -b myfeature develop Switched to a new branch "myfeature" |
Les fonctionnalités terminées peuvent être fusionnées dans la branche develop pour être ajoutées à la prochaine version :
$ git checkout develop Switched to branch 'develop' $ git merge --no-ff myfeature Updating ea1b82a..05e9557 (Résumé des changements) $ git branch -d myfeature Deleted branch myfeature (was 05e9557). $ git push origin develop |
L’option --no-ff va créer un nouveau commit lors de la fusion, même si la fusion aurait pu se faire avec un fast-forward. Cela évite de perdre l’information de l’existence historique d’une branche de fonctionnalité et groupe ensemble tous les commits qui ont été ajoutés à la fonctionnalité.
Regardez la différence :
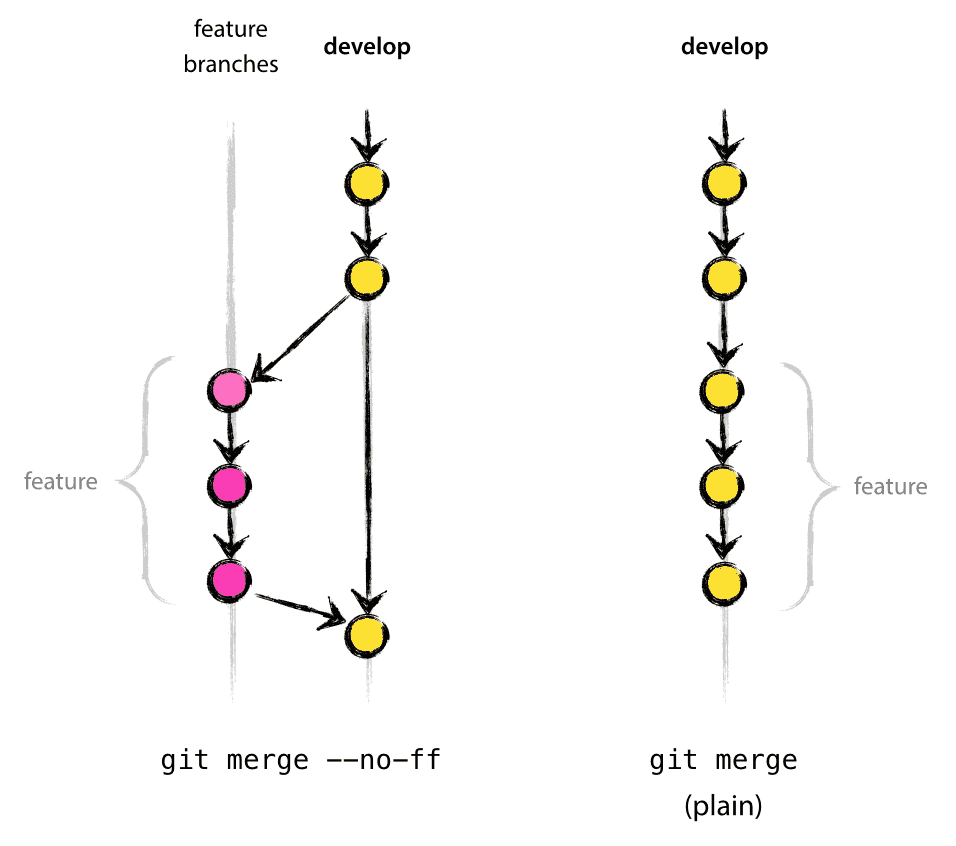
Dans le deuxième cas, il est impossible de voir à partir de l’historique de Git quel groupe de commits a implémenté une fonctionnalité – il faudrait lire manuellement tous les messages de logs. Supprimer une fonctionnalité (c’est à dire un ensemble de commits) est un vrai casse-tête dans la deuxième situation, alors que c’est très facile à faire lorque l’option --no-ff a été utilisée.
Oui, cela va créer quelques commits (vides) supplémentaires, mais le gain est tellement supérieur au coût.
Malheureusement, je n’ai pas encore trouvé de manière de faire de --no-ff l’option par défaut de git merge, mais ça devrait vraiment l’être.
Les branches de version servent à préparer les nouvelles versions de production. Elles permettent les optimisations de dernière minute. De plus elles permettent la correction d’anomalies mineures et la préparation des méta-données pour une version (numéro, date de compilation, etc.). En faisant tout ce travail sur une branche de version, la branche develop peut incorporer des fonctionnalités pour la prochaine version majeure.
Le bon moment pour créer une nouvelle branche de version depuis develop est quand develop reflète l’état désiré de la nouvelle version. A minima toutes les fonctionnalités visées pour la version à venir doivent être fusionnées dans develop à ce moment-là. Toutes les fonctionnalités visées pour les prochaines versions ne le sont pas – elles doivent attendre jusqu’à ce que la branche de version bifurque.
C’est précisément au début d’une branche de version que la prochaine version se voit assigné un numéro de version – et pas avant. Avant ce moment, la branche develop reflète les changements pour la « prochaine version » mais sans forcément savoir si cette « prochaine version » sera la 0.3 ou la 1.0, du moins pas avant que la branche de version soit créé. Cette décision est prise au début de la nouvelle branche de version et dépend des règles mise en place sur les changements de numéros de version.
Les branches de version sont créées à partir de la branche develop. Par exemple, disons que la version 1.1.5 est la version courante de production et que nous avons une nouvelle version majeure qui arrive. L’état de develop est prêt pour la « prochaine version » et nous avons décidé que cela deviendra la version 1.2 (plutôt que 1.1.6 ou 2.0). Donc nous bifurquons et donnons à la branche de version un nom qui reflète le nouveau numéro de version :
$ git checkout -b release-1.2 develop Switched to a new branch "release-1.2" $ ./bump-version.sh 1.2 Files modified successfully, version bumped to 1.2. $ git commit -a -m "Bumped version number to 1.2" [release-1.2 74d9424] Bumped version number to 1.2 1 files changed, 1 insertions(+), 1 deletions(-) |
Après avoir crée une nouvelle branche, et nous être positionné dessus, nous incrémentons le numéro de version. Ici, bump-version.sh est un script shell fictif qui change quelques fichiers dans notre dossier de travail pour refléter la nouvelle version. (Cela peut bien évidemment être un changement manuel – le propos étant que certains fichiers changent.) Puis, le changement de numéro de version est enregistré.
Cette nouvelle branche pourra exister pendant un moment, jusqu’à ce que la version soit déployée pour de bon. Pendant ce temps, des correctifs pourront être appliqués à cette branche (plutôt que sur la branche develop), et par conséquent en attendant la prochaine version majeure.
Quand l’état de la branche de version est prêt à devenir une vraie version, quelques actions doivent êtres effectuées. Premièrement, la branche de release est fusionnée dans master (puisque chaque commit sur master est une nouvelle version par définition, souvenez-vous). Ensuite, ce commit sur master doit être tagué pour pouvoir faire simplement référence par la suite à cette version historique. Enfin, les changements fais sur la branche de version doivent être reversés dans develop, afin que les version futures contiennent aussi ces correctifs.
Les deux premieres étapes dans Git :
$ git checkout master Switched to branch 'master' $ git merge --no-ff release-1.2 Merge made by recursive. (Résumé des changements) $ git tag -a 1.2 |
La version est maintenant terminée et taguée pour toute référence future.
Remarque : Vous pouvez tout aussi bien vouloir utiliser les options -s or -u <clef> pour signer votre tag de manière chiffrée.
Pour garder les changements effectués dans la branche de version, nous avons besoin de les fusionner dans develop. Avec Git :
$ git checkout develop Switched to branch 'develop' $ git merge --no-ff release-1.2 Merge made by recursive. (Résumé des changements) |
Cette étape peut mener à une conflit de fusion (probablement même, puisque nous avons changé le numéro de version. Si c’est le cas, corrigez-le et faîtes un commit.
Maintenant nous avons vraiment terminé et la branche de version peut être supprimée, puisque nous n’en avons plus besoin :
$ git branch -d release-1.2 Deleted branch release-1.2 (was ff452fe). |
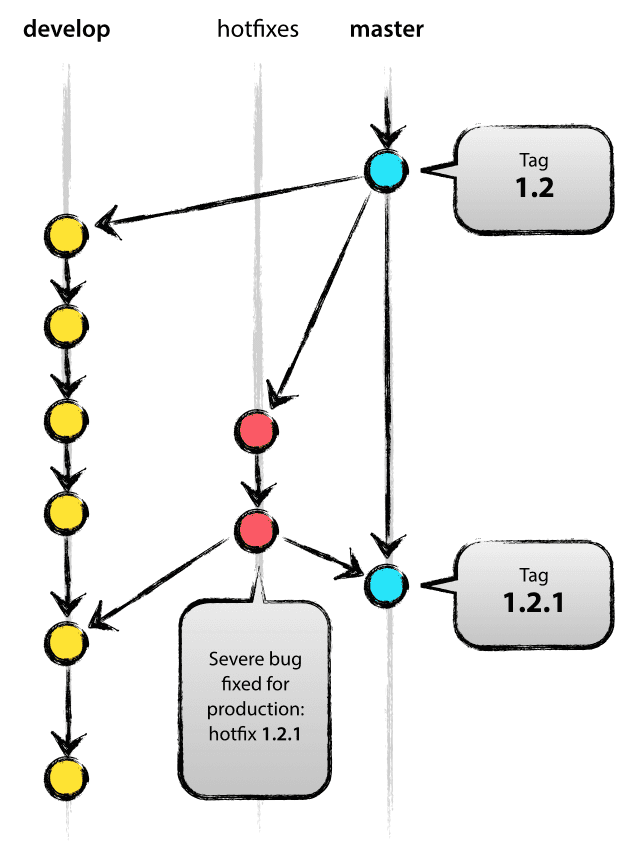
Les branches de correctifs ressemblent beaucoup aux branches de version, dans le sens où elles sont également destinées à préparer une nouvelle version de production, bien que non planifiées. Elles viennent de la nécessité d’agir immédiatement sur un état indésirable d’une version en production. Quand une anomalie critique doit être résolu immédiatement, une branche de correctif peut être crée à partir du tag correspondant sur la branche master qui marque la version de production.
L’objectif est que le travail des membres de l’équipe (sur la branche develop) puisse continuer, pendant qu’une autre personne prépare un correctif rapide pour la production.
Les branches de correctif sont créées à partir de la branche master. Par exemple, disons que la version 1.2 est la version qui tourne actuellement en production et que plusieurs anomalies posent problème. Dans le même temps les modifications effectuées sur develop sont encore instables. Nous pouvons alors créer une branche de correctif et commencer à corriger le problème :
$ git checkout -b hotfix-1.2.1 master Switched to a new branch "hotfix-1.2.1" $ ./bump-version.sh 1.2.1 Files modified successfully, version bumped to 1.2.1. $ git commit -a -m "Bumped version number to 1.2.1" [hotfix-1.2.1 41e61bb] Bumped version number to 1.2.1 1 files changed, 1 insertions(+), 1 deletions(-) |
N’oubliez pas de modifier le numéro de version après la création de la branche !
Ensuite, corrigez le bug et enregistrez le correctif dans un ou plusieurs commits séparés.
$ git commit -m "Fixed severe production problem" [hotfix-1.2.1 abbe5d6] Fixed severe production problem 5 files changed, 32 insertions(+), 17 deletions(-) |
Lorsque c’est terminé, le correctif a besoin d’être reporté dans master, mais aussi dans develop, de manière à garantir que le correctif sera également inclus dans la prochaine version. C’est en tout point similaire à la manière dont les branches de version sont finalisées.
Premièrement, mettez à jour master et taguez la version :
$ git checkout master Switched to branch 'master' $ git merge --no-ff hotfix-1.2.1 Merge made by recursive. (Résumé des modifications) $ git tag -a 1.2.1 |
Remarque : Vous pouvez tout aussi bien vouloir utiliser les options -s or -u <clef> pour signer votre tag de manière chiffrée.
Ensuite, déployez également le correctif dans develop :
$ git checkout develop Switched to branch 'develop' $ git merge --no-ff hotfix-1.2.1 Merge made by recursive. (Résumé des modifications) |
La seule exception à la règle ici est que, lorsqu’une branche de version en cours de developpement existe, le correctif a besoin d’être reporté dans cette branche de version, plutôt que dans develop. Le report de l’anomalie dans la branche de version finira par être reporté dans develop à son tour, lorsque la branche de version sera terminée. (Si le travail en cours sur develop nécessite que l’anomalie soit corrigée immédiatement sans attendre la fin de la branche de version, vous pouvez tout aussi bien reporter dès à présent le correctif également sur develop.)
Enfin, supprimer la branche temporaire :
$ git branch -d hotfix-1.2.1 Deleted branch hotfix-1.2.1 (was abbe5d6). |
Bien qu’il n’y ait rien de bien révolutionnaire dans ce modèle de développement, l’illustration qui figure au début de cet article s’est révélée particulièrement utile dans nos projets. C’est un modèle mental facile à appréhender et il permet de développer une appropriation collective des processus de branches et de versions.
Enfin, voici une version PDF en haute résolution du modèle. Imprimez-le et accrochez le au mur pour avoir une référence sous les yeux à tout moment.
NdT : Pour aller plus loin, nous vous recommandons de lire cette introduction à Gitflow, dont le but est de vous aider à suivre ce modèle de développement. Il existe d’autres workflows Git que vous pouvez tester comme le Github Flow, le Gitlab Flow, celui utilisé chez AOE ou cette comparaison de workflow chez Atlasssian, l’essentiel étant de l’adapter à votre contexte et à votre équipe.